Transformer学习笔记
Transformer整体结构
Transformer是一个用于NLP序列到序列(seq2seq)任务的模型架构,创新的引入了自注意力机制,在处理序列数据时表现出色。 它主要由以下两个部分组成:Encoder和Decoder,整体结构如下图。
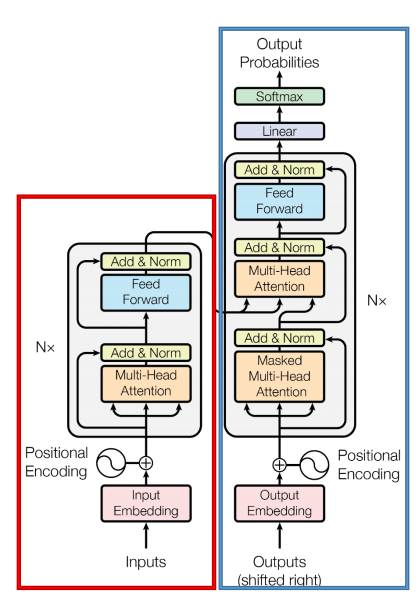
- Encoder:红色部分;Decoder:蓝色部分。
- Input(BPE+PE):输入由两部分组成,分别是BPE向量和位置向量。
- BPE(Byte Pair Encoding):分词算法,通过将之前没见过的单词切分成见过的subword,从而表达更多的单词,再通过embedding获得向量表示。
- PE(Positional Encoding): 在原有的embedding上加上一个位置向量,以区分不同位置的相同单词。
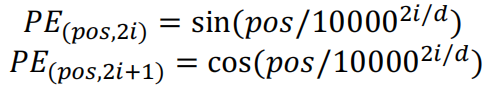
- Model:Encoder和Decoder块的堆叠。Nx是堆叠的Transformer block的数量,论文中Nx=6。
- Onput(Liner+Softmax):输出在词表上的概率分布。
- Loss function:标准交叉熵函数。
总的来说,Transformer的工作流程如下:
- 输入的文本进行分词后,每个词会获得一个向量表示即embedding,这个embedding由BPE和PE相加得到。因此,一句话的向量表示时词向量的堆叠,即一个向量矩阵。
- 将得到的表示向量矩阵传入Encoder中,经过六个Encoder后得到输入句子的编码矩阵 \(X\)。
- 编码矩阵 \(X\) 会进入Decoder中,Decoder会根据已输入的 \(i\) 个词依次预测第 \(i+1\)个词。为了防止模型看到后面的词来预测前面的输入,会采取mask操作盖住 \(i+1\) 后的词。
Encoder
 Encoder部分包含三个部分:
Encoder部分包含三个部分:
- 多头注意力层(
Multi-Head Attention) - 前馈神经网络(
Feed Forward) - 残差连接(红线部分,即
Add操作)和正则化层(Norm操作)
1. Muti-Head Attention:多头注意力机制
Muti-Head Attention是由多个Self-Attention组成的,所以先着重关注Self-Attention的内部结构。Self-Attention希望每个token自主选择应该关注这句话中的哪些token,并进行信息的整合。
1.1 Masked self-attention:掩码自注意力机制
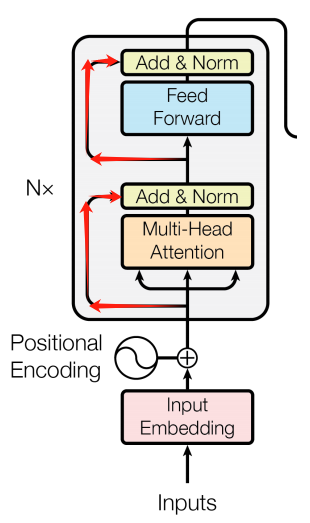
 可以看到,这一部分接收的输入是 $ Q, K, V$
三个矩阵,这部分的计算方式如下:
可以看到,这一部分接收的输入是 $ Q, K, V$
三个矩阵,这部分的计算方式如下:
\[ \rm Attention(\it Q,K,V)=\rm softmax(\it QK^T)V. \]
其中, \(Q, K, V\) 是由输入 \(X\) 与三个不同的权重矩阵 \(W^Q,W^K,W^V\) 相乘的结果,本质上都是 \(X\) 的线性变换。
设 \(X\) 是 \(m\times n\) 的矩阵, \(W^Q,W^K,W^V\) 是 \(n\times k\) 的矩阵,最后得到的 \(Q,K,V\) 则是\(m\times k\)的矩阵。
- \({QK}^T\) 相乘后得到\(m\times m\)的矩阵;
- 经过\(\rm softmax\)层后得到注意力分数的分布,矩阵维度仍是 \(m\times m\);
- 注意力分数与\(V\)相乘,还原成维度为 \(m\times k\) 的矩阵输出,与输入的\(X\)一一对应。
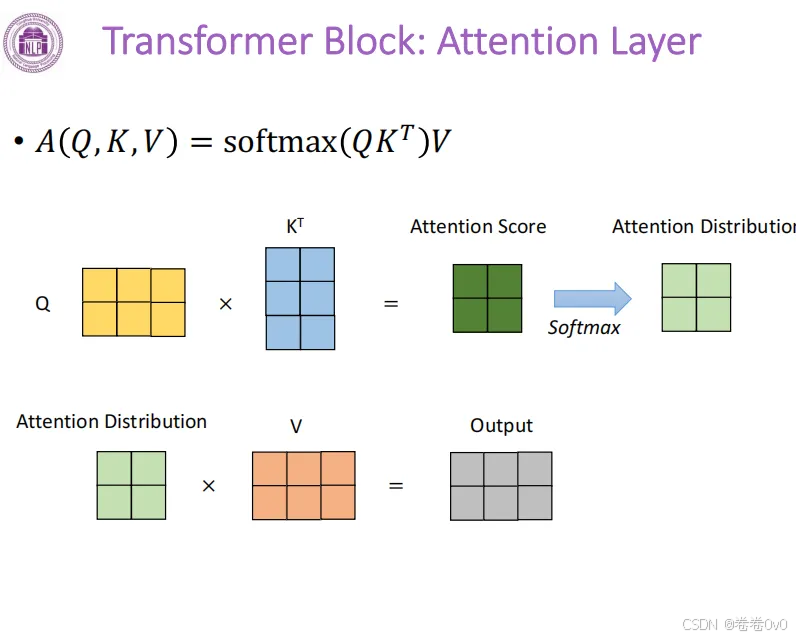
总结来说,整个Attention计算过程就是,矩阵 \(Q,K\) 相乘得到注意力分数,通过scale系数对规模进行放缩,再通过softmax将注意力分数变成一个概率分布,最后与对应的矩阵 \(V\) 进行矩阵乘法,实现对矩阵 \(V\) 的加权平均。
详细计算过程可以看这篇博客:一文搞定自注意力机制。
在这里要先和RNN里的注意力机制做一下区分:
- RNN的注意力机制:给定一个 \(query\) 向量和 \(value\) 向量的集合,基于 \(query\) 向量对 \(value\) 向量进行加权平均,采用 \(q\) 和 \(v\) 计算注意力分数。
- Transformer采用的是基于点积的注意力机制,给定 \(query\) 向量、\(key\)和\(value\)向量对的集合,采用$ q$ 和 \(k\) 的点积来计算注意力分数。
1.2 Scaled dot-product attention:引入放缩系数
随着key向量维度的增长,\(q\) 和 \(k\) 的点积得到的标量(值)的方差也会变大,如果直接作用到softmax函数,得到的概率分布会变得更加尖锐,大部分概率分布接近于0,导致梯度越来越小,不利于参数的更新。
所以在这个基础上,引入一个scaled系数,组成一个完整的Scaled
dot-product attention模块,即在原有的基础上除以一个 \(\sqrt{d_k}\)
,即向量维度的开方。因此,最终的计算方式如下:
\[\rm Attention(\it Q,K,V)=\rm softmax(\it \frac {QK^T}{\sqrt {d_k}})V.\]
1.3 Muti-Head Attention:多头注意力机制
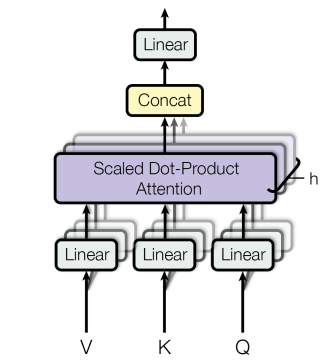
Transformer采用了多个结构相同,但是参数不同的注意力模块(h个)组成多头注意力机制。每个注意力头的计算方式相同,但每个注意力头 \(i\) 对应权重矩阵的\(W_i^Q,W_i^K,W_i^V\)不同。
即每个注意力头中 X 乘上的权重矩阵不同,每个注意力头进行不同的线性变换。
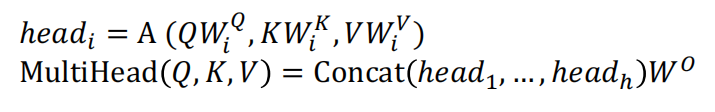
- Input:如果是第一层Encoder,输入是embedding和位置编码的相加,非第一层的Encoder的输入是前一层的输出。
- Scaled dot-product attention层:计算注意力分数。
- Concat层:将注意力头得到的输出进行拼接,再通过线性层整合得到最终输出。
- Output:Muti-head attention模块的输出经过残差连接和正则化后,输入到后面的前馈神经网络。
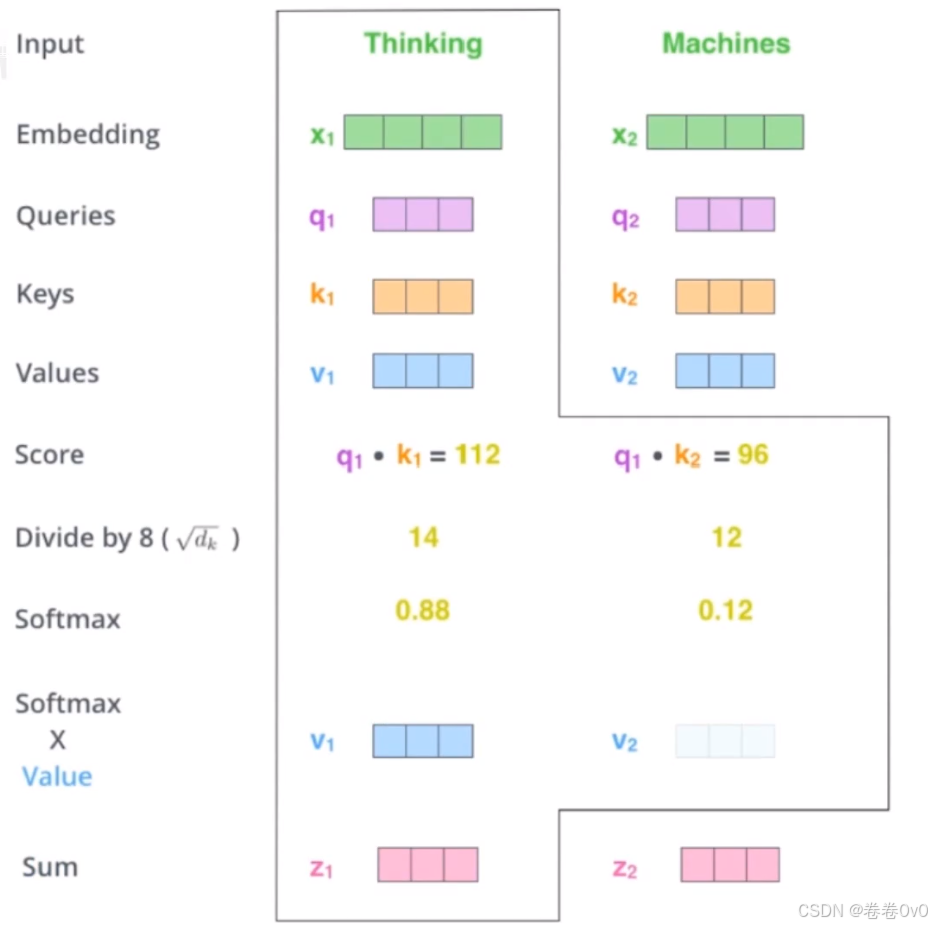
1.4 一个embedding计算例子
Step1. 计算单词Thinking、Machines的embedding,得到 \({x_1,x_2}\)。
Step2. \({x_1,x_2}\) 与权重矩阵 $ W^Q, W^K, W^V$ 相乘,得到 \({q_1,k_1,v_1}\)。
Step3. 计算注意力分数,即$ {q_1,k_1}$的点积,这里假设 \({q_1 · k_1}=112, {q_2· k_2}=96\) ($ {q_i,k_i}$ 堆叠起来就是矩阵 \(Q, K\) ,即 $ {QK}^T$ 计算的结果)。
Step4. 除以scaled系数\(\sqrt {d_k}\),一般来说是向量维度的开方,这里假设\(d_k=64\)。
Step5. 通过计算softmax得到注意力分数的概率分布: \[ \rm softmax\it (x)=\frac{e^{x_i}}{\sum_i e^{x_i}},\rm softmax (x_1)=\frac{e^{12}}{e^{14}+e^{12}}=0.88,\rm softmax (x_2)=\frac{e^{14}}{e^{14}+e^{12}}=0.12. \]
Step6. 将得到的概率分布矩阵与$ v_1$ 相乘,得到最后的输出$ z_1$ (矩阵$ V$ 是每个$ v_i$ 堆叠起来的结果,相乘后的$ z_i$ 堆叠起来的得到最后的输出矩阵 \(Z\) 。
2. Feed-Forward Network:前馈神经网络
这部分时两层的MLP层(全连接层),第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下: \[ max(0,XW_1+b_1)W_2+b_2. \]
3. Add&Norm:残差连接与正则化
这一层包括残差连接(Residual
connection)和正则化(Layer
normalization),就是将每一小块的输入和这一小块的输出相加后再输入到下一块,即图中的红线部分。计算公式如下:
- 第一个Add&Norm层:\(LayerNorm(X+MultiHeadAttention(X))\)
- 第二个Add&Norm层:\(LayerNorm(X+FeedForward(X))\)
残差连接借鉴于CV领域中的ResNet,将输入输出直接相加,缓解模型过深导致的梯度消失问题。
正则化会将输入的向量变成一个均值为0,方差为1的分布,缓解梯度消失/爆炸问题。
Decoder
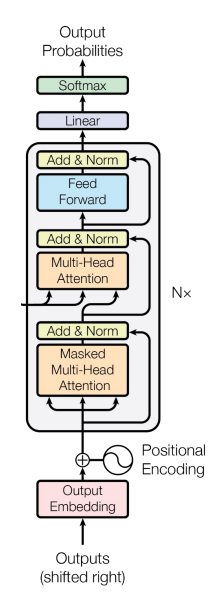 Decoder部分包含四个部分:
Decoder部分包含四个部分:
- 采用了掩码的多头注意力层(
Masked Multi-Head Attention) - 多头注意力层(
Multi-Head Attention) - 前馈神经网络(
Feed Forward) - 残差连接(
Add操作)和正则化层(Norm操作)
1. Masked self-attention:掩码自注意力机制
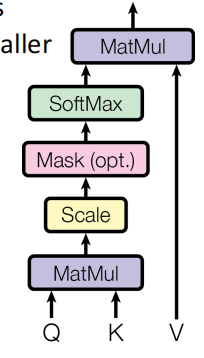
为了限制保证Decoder端生成文本的时候是顺序生成的,不会在生成第i个位置的时候参考i+1位置的信息,使用mask让$ Q, K$相乘得到的注意力分数的上三角部分的值变成负无穷大。
这样一来,它们经过softmax之后那些位置对应的概率会变为0,使得模型在当前输出的步骤看不到后面的单词。注意 Mask 操作是在 Self-Attention 里 Softmax 层之前使用的。
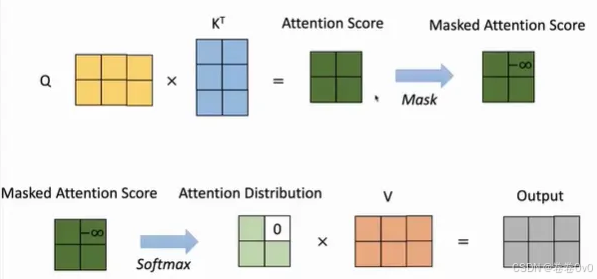
2. Muti-head attention:多头注意力机制
Decoder里这个Muti-head attention模块与Encoder里的略有不同,简而言之,Decoder的$ Q$分为两种情况:
- 如果是第一个Decoder block,则通过输入矩阵$ X$ 计算得到$ Q$;
- 如果不是第一个,则通过上一Decoder block的输出$ Z$ 计算得到 $ Q$。
而Decoder的 \({K,V}\) 则是通过Encoder的输出 \(C\) 计算得到的。
这个设计是为了帮助Decoder每一步生成都可以关注和整合Encoder端每个位置的信息,让每一个单词都可以在Decoder的时候利用到Encoder所有单词的信息。
3. 具体计算过程
详细计算过程可以参考这篇博客:Transformer模型详解。这里引用其中的几张图总结一下:
Step1. 输入单词向量矩阵 $ X$ 和Mask矩阵 $ M$ 。 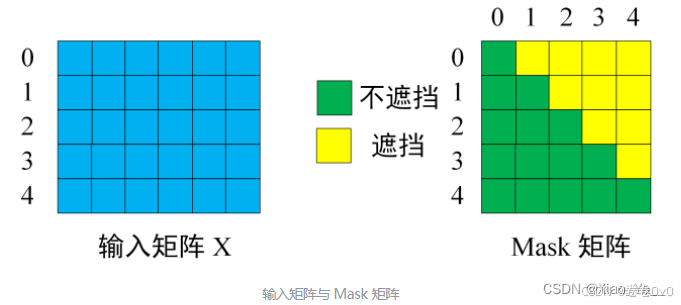
Step2. 像之前一样通过输入矩阵$ X$ 得到矩阵 \({Q,K,V}\) 后,计算 $ {QK}^T$ 。 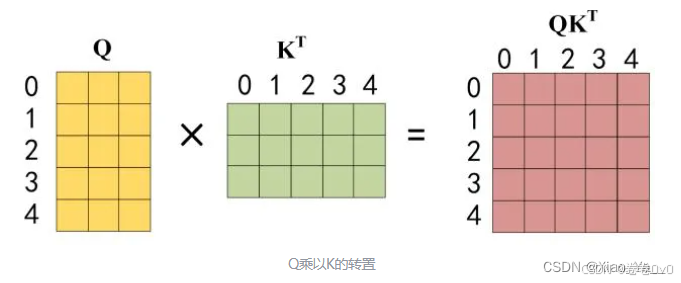
Step3. 将 \({QK}^T\) 与Mask矩阵 \(M\) 相乘,使得矩阵上三角值为0(被遮盖)。
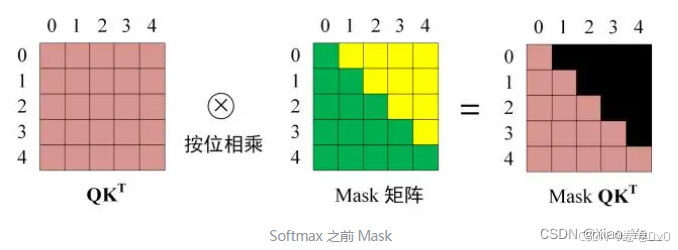
Step4. \({Mask \
QK}^T\) 与矩阵\(V\) 相乘得到输出
\(Z\) ,其中 \(Z\) 的每一行 \(z_i\) 只包含单词 \(i\) 的信息。 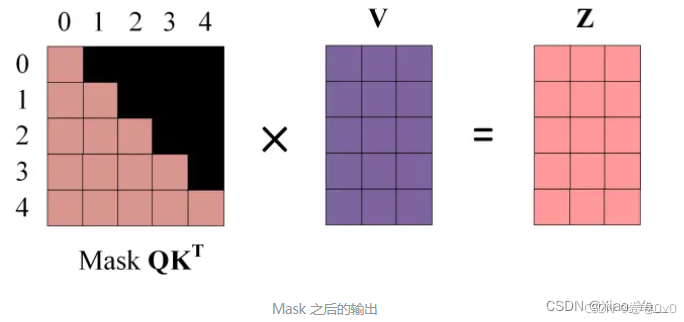
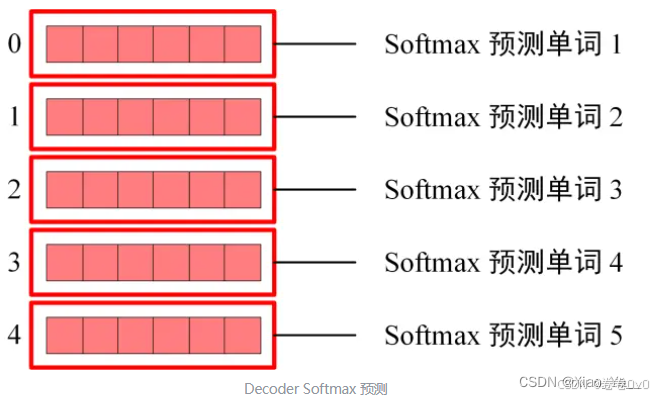
Step5. Softmax 根据输出矩阵的每一行预测下一个单词。
Other tricks
- 训练过程采用了Checkpoint averaging技术,使用Adam优化器进行参数更新。
- 为了提高模型的训练效果防止过拟合,在残差连接之前加上了dropout。
- 在输出层加入label smoothing来提高训练效率。
- 在生产过程中采用了更复杂的一个生成策略(Auto-regressive decoding with beam search and length penalties)。
Advantage
- 强表示能力,可以迁移到别的NLP任务中;
- 结构本身适合并行计算,对目前GPU等加速设备非常友好;
- 对attenition机制进行可视化,可以发现注意力模块很好地建模了句子中token之间的关系;
- 给预训练语言模型带来了很多启发(Bert, GPT),成为目前预训练模型最主要的一个框架。
Disadvantage
- 模型本身对参数非常敏感,优化过程很困难;
- 模型复杂度是文本长度n的平方,导致对长文本束手无策,当前很多模型会设置一个最大输入长度512。
原始论文:《Attention is all you need》(NeurIPS 2017)