基于 Transformers 的 NER
Reference:【HuggingFace Transformers-实战篇】命名实体识别
任务简介
命名实体识别(Named Entity Recognition,
NER)是信息抽取的一个子任务,旨在提取文本信息中的关键实体并识别其类型,常见的通用类型有PER(人物)、LOC(位置)、ORG(组织)等。
 目前常见的数据标注方法有:IOB1、IOB2、IOOES、IOE等。
目前常见的数据标注方法有:IOB1、IOB2、IOOES、IOE等。
以IOB2为例,I表示实体内部,O表示实体外部,B表示实体开始,一般的数据格式如下:乔,B-PER、布,I-PER、斯,I-PER。如果是IOBES标注,E表示实体的结束,S表示一个词单独构成一个实体。有时会用M替代I,本质上是一个意思。
任务评估指标
- Precision (P) :预测正确的实体个数 / 预测出的实体个数(预测出的不一定对);
- Recall (R) :预测正确的实体个数 / 实际上的实体个数;
- F1:F1认为准确率P和召回率R同等重要,\(F_1=\frac {2PR}{P+R}\)。(还有F2和F0.5)
基于Transformers的中文命名实体识别
对于中文来说,token是每个字,实际上模型是对每个token进行标签分类,模型结构选择
ModelForTokenClassification。数据集选择peoples_daily_ner,模型选择hfl/chinese-macbert-base。
Step1 导入相关包
1 | |
Step2 加载数据集
1 | |
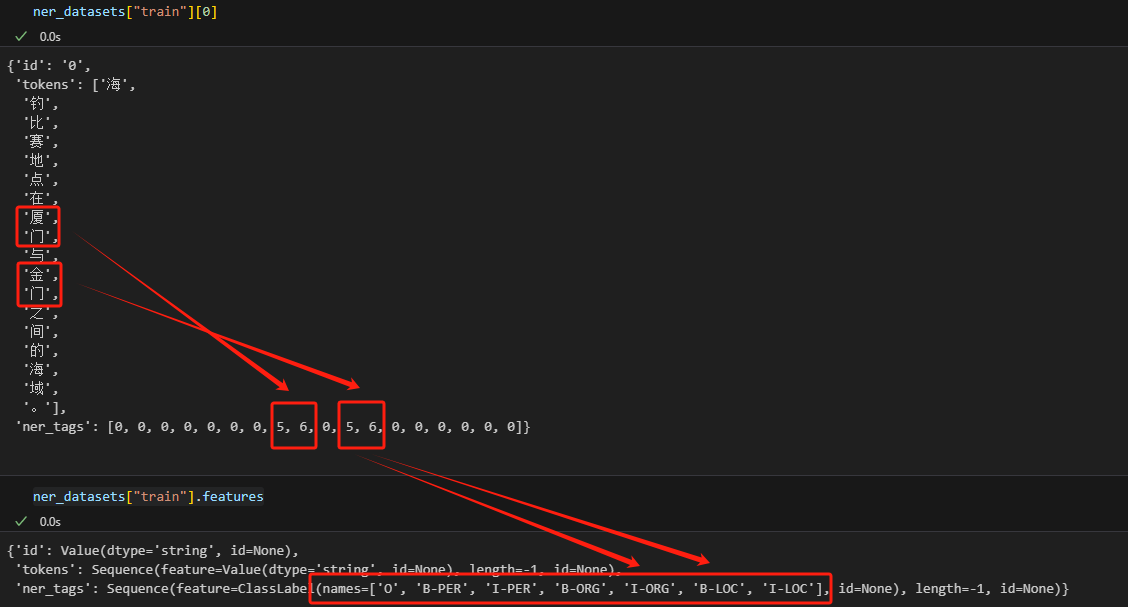
可以看到,在这个数据集中已经做了标签的映射,厦门、金门分别对应5、6分别对应B-LOC、I-LOC。
1 | |

Step3 数据集预处理
对于分词后的数据(中文就是分字),要指定is_split_into_words=True,不然会对每个字都包裹
[CLS] 和[SEP] ,实际上对每句话包裹 [CLS] 和 [SEP] 就可以了。


此外,在计算的过程中,我们要让模型知道哪些是有实际语义、哪些是
[CLS]、[SEP] 这种特殊符号,因此还要遍历word_ids,将
[CLS]、[SEP]
对应的None值置为-100,这个值是交叉熵损失函数计算时会自动忽略的值。将每句话最后得到的编码结果用label_ids存储起来,写入字段labels。
1 | |
这里借助word_ids来进行标签映射的原因是,对于中文,一个字对应一个label;但对于英文单词的分词,比如说interesting
word,虽然是两个单词但分词后是对应了五个位置的编码的,所以要借助word_ids来区分这五个编码里哪几个是interesting,哪几个是word。即使interesting被分成很多词,label_ids.append(label[word_id])会让它的所有分词结果对应同一个标签。


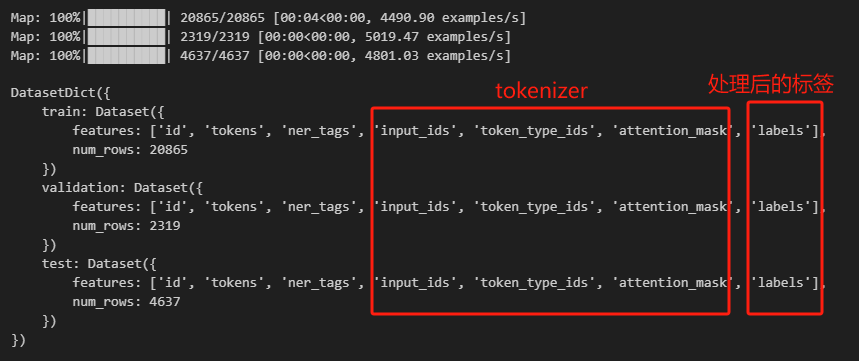
最后,数据集的特征除了原始字段,多了tokenizer带来的三个字段,以及每句话的编码结果labels。
Step4 创建模型
分词完成后,创建一个AutoModelForTokenClassification模型。对于所有的非二分类任务,切记要指定num_labels,否则会报device错误。
1
model = AutoModelForTokenClassification.from_pretrained("hfl/chinese-macbert-base", num_labels=len(label_list))
Step5 创建评估函数
命名实体识别任务要用到一个序列评估函数seqeval,可以pip安装也可以从下载后从本地加载。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import numpy as np
# 本地加载 seqeval
seqeval = evaluate.load("seqeval_metric.py")
def eval_metric(pred):
predictions, labels = pred
predictions = np.argmax(, axis=-1)
# 将id转换为原始的字符串类型的标签
true_predictions = [
[label_list[p] for p, l in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for p, l in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
result = seqeval.compute(predictions=true_predictions, references=true_labels, mode="strict", scheme="IOB2")
return {
"f1": result["overall_f1"]
}
Step6 配置训练参数
1 | |
Step7 创建训练器
1 | |
Step8 模型训练
1 | |
Step9 模型评估
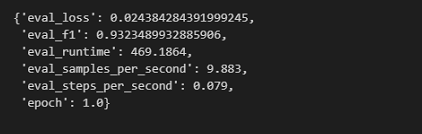
可以在测试集上对模型进行评估。 1
trainer.evaluate(eval_dataset=tokenized_datasets["test"])
Step10 模型预测
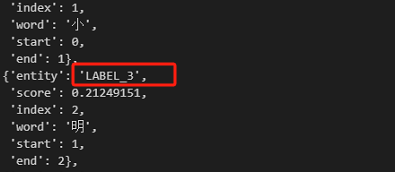
使用pipeline使用模型进行预测。可以发现预测结果是按token返回的,并且对应的标签是LABEL_3,这是因为模型config里默认的id2label是这样对应的。
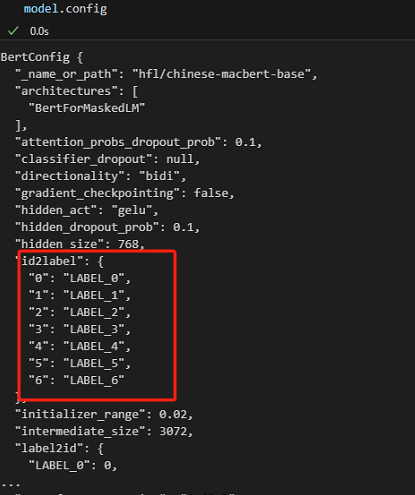
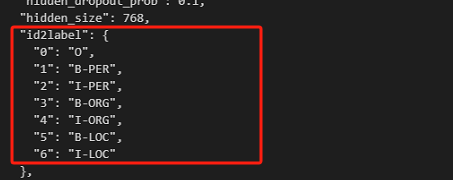
重新写一个id2label对默认的进行覆盖。
1 | |
此外,对于NER任务,如果不希望token的标签是一个一个返回,可以指定aggregation_strategy="simple"让模型返回完整实体。如果模型是基于GPU训练的,那么推理时要指定device=0。
1 | |
最后得到的结果是这样的,可以发现词与词之间使用空格的,因为tokenizer在解码时默认会用空格连接token。
 可以通过
可以通过start和end进行取词。进一步规整预测结果。
1 | |
