HuggingFace Transformers 显存优化策略
Reference:【HuggingFace Transformers-实战篇】显存优化策略,字长模型:LP32、ILP32,PPT
显存占用因素
- 模型权重:即模型的参数量。BERT-Base模型参数量为110M(0.1B),BERT-Large模型参数量为330M(约0.3B)。它们都是LP32数据模型,因此每个参数需要占四个字节,
总空间 = 四字节 × 模型的参数量。 - 优化器状态:优化器的状态也需要存储在显存中。以常用的优化器Adam为例,它需要为每个参数存储八个字节的信息。
- 梯度:在进行反向传播时,梯度信息也需要存储,每个梯度占用四个字节。
- 前向激活值:即计算过程中的中间变量也需要存储,其显存占用取决于序列长度、隐层维度、batch size等多个因素。
除此之外,一些其他的因素,如临时缓冲区也会占用显存。
显存优化策略
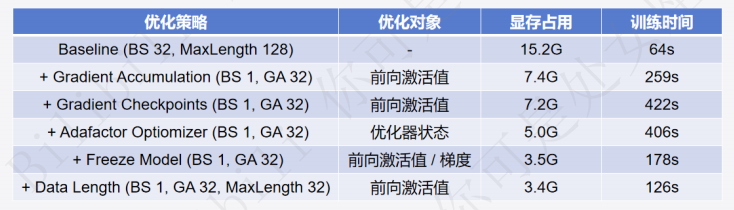
为了在4G显存的情况下也能跑BERT-Large,可以尝试以下几种优化策略:
| 优化策略 | 优化对象 |
|---|---|
| 梯度积累(Gradient Accumulation, GA) | 前向激活值 |
| 梯度选择性保存(Gradient Checkpoints, GC) | 前向激活值 |
| 选择显存占用更少的优化器(如Adafactor) | 优化器状态 |
| 参数冻结(Freeze Model) | 前向激活值、梯度 |
| 数据长度(Data MaxLength) | 前向激活值 |
对比试验
使用hfl/chinese-macbert-large进行优化策略前后的效果对比,每次更新策略后要重启kernel,不然会有中间变量留存。优化的主要思想就是用时间换空间。 (因为我没GPU,训练的时候CPU占用率都是100%没有对比效果,主要看时长变化吧。使用GPU训练的可以打开任务管理器看优化效果,参考up给出的表。)
原视频github项目地址:https://github.com/zyds/transformers-code/
maxlength=128, batchsize(BS)=32
处理数据时将padding限制为最大长度,不再动态填充。 1
2
3
4def process_function(examples):
tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True, padding="max_length")
tokenized_examples["labels"] = examples["label"]
return tokenized_examples1
2
3
4
5
6
7
8
9
10
11
12
13# 1. base
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=32, # 训练时的batch_size
per_device_eval_batch_size=32, # 验证时的batch_size
num_train_epochs=1, # 训练轮数
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="f1", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型

maxlength=128, BS=1, GA=32
batchsize越大对机器计算性能要求较高,但batchsize设置过低可能会影响模型效果,所以可以采取缓解措施,即设置梯度积累gradient_accumulation_steps=32。这样即使batchsize=1,他会每计算32条数据以后一起进行一次优化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14# test_1:使用梯度积累策略
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=1, # 训练时的batch_size
gradient_accumulation_steps=32, # *** 1. 梯度累加 ***
per_device_eval_batch_size=1, # 验证时的batch_size
num_train_epochs=1, # 训练轮数
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="f1", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型

maxlength=128, BS=1, GA=32, GC=True
还可以针对保存中间变量的策略进行优化,设置gradient_checkpointing=True,不保存全部中间变量,而是选择性的存一些。对于没存下来的激活值,可以在反向传播计算梯度的时候重新计算,小模型可能优化效果不明显但是放到大语言模型上是很有用的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# test_2:增加梯度检查点
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=1, # 训练时的batch_size
gradient_accumulation_steps=32, # *** 1. 梯度累加 ***
gradient_checkpointing=True, # *** 2. 梯度检查点 ***
per_device_eval_batch_size=1, # 验证时的batch_size
num_train_epochs=1, # 训练轮数
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="f1", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型
maxlength=128, BS=1, GA=32, GC=True, Adafactor
选择显存占用更少的优化器Adafactor,TrainingArguments默认使用的是AdamW。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# test_3:替换占用显存更小的优化器
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=1, # 训练时的batch_size
gradient_accumulation_steps=32, # *** 1. 梯度累加 ***
gradient_checkpointing=True, # *** 2. 梯度检查点 ***
optim="adafactor", # *** 3. adafactor优化器 ***
per_device_eval_batch_size=1, # 验证时的batch_size
num_train_epochs=1, # 训练轮数
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="f1", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型
train_args

maxlength=128, BS=1, GA=32, GC=True, Adafactor, Freeze
以文本分类任务为例,模型的结构是Bert+全连接层,那么其实可以把Bert的参数冻结住,只训练全连接层的参数来降低显存。即冻结特征提取模块参数,只训练任务层参数,不仅显著降显存还能提搞训练速度(当然模型效果可能也会受影响)。
代码实现就是遍历Bert模型里的所有参数,设置requires_grad = False。
1
2
3
4
5
6
7
8
9
10# test_4: 参数冻结
for name, param in model.bert.named_parameters():
param.requires_grad = False
trainer = Trainer(model=model,
args=train_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=eval_metric)

maxlength=32, BS=1, GA=32, GC=True, Adafactor, Freeze
最后,还可以在数据预处理部分减小data
length,即减小max_length的值。这个操作对于模型的效果影响很大,因为把输入截得很短的话会很影响模型效果,主要还是按需选择。
1
2
3
4
5# test_5:减小maxlength
def process_function(examples):
tokenized_examples = tokenizer(examples["review"], max_length=32, truncation=True, padding="max_length")
tokenized_examples["labels"] = examples["label"]
return tokenized_examples