Reference:【HuggingFace
Transformers-入门篇】基础组件之Evaluate
Evaluate库 包含各种机器学习模型的评估函数,可以很方便的加载各种任务的评估函数。
查看支持的评估函数
list_evaluation_modules会给出Huggingface支持的评估函数,更完整的评估函数可以在官网说明中 查看。
1 2 3 import evaluate
对于支持的评估函数有两种实现:社区实现和官方实现。如果不想要社区实现,可以通过设置参数include_community=False来实现。想要知道更多细节的话,可以设置参数with_details=True。
1 evaluate.list_evaluation_modules(include_community=False , with_details=True )
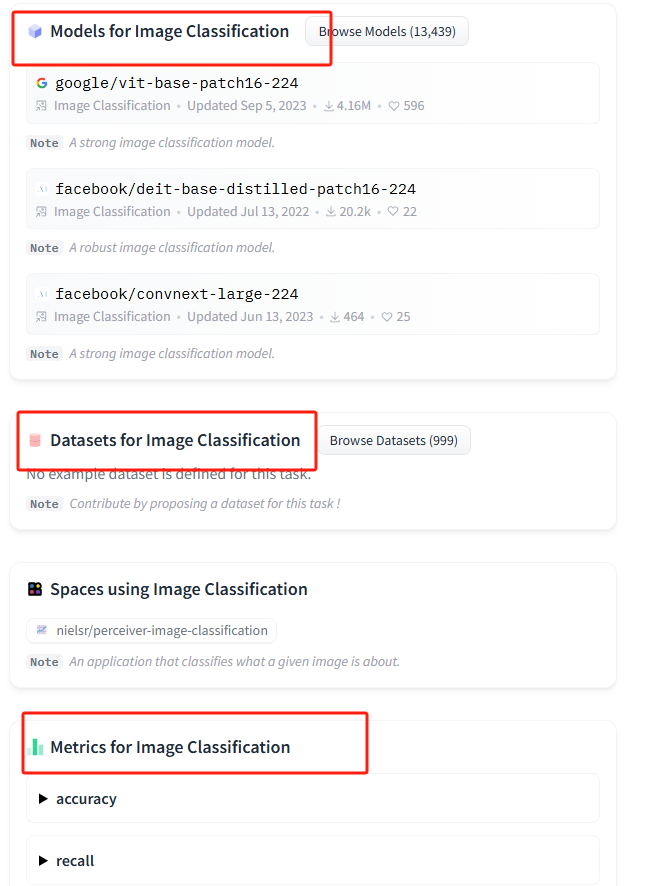
huggingface的task面板 查看。选择相应的任务后,huggingface会提供一个demo,以及适合这个任务的models、datasets和metrics。
加载评估函数
1 accuracy = evaluate.load("accuracy" )
查看函数说明
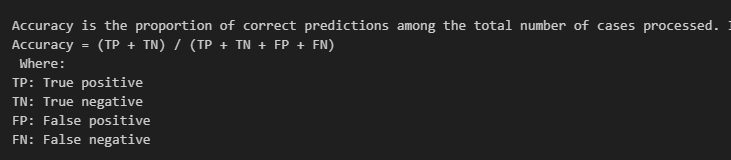
查看函数说明可以去看源码,但还有更简便的方式,就是通过accuracy的属性description进行查看。他会对这个评估函数的计算方式进行简单介绍。
1 print (accuracy.description)
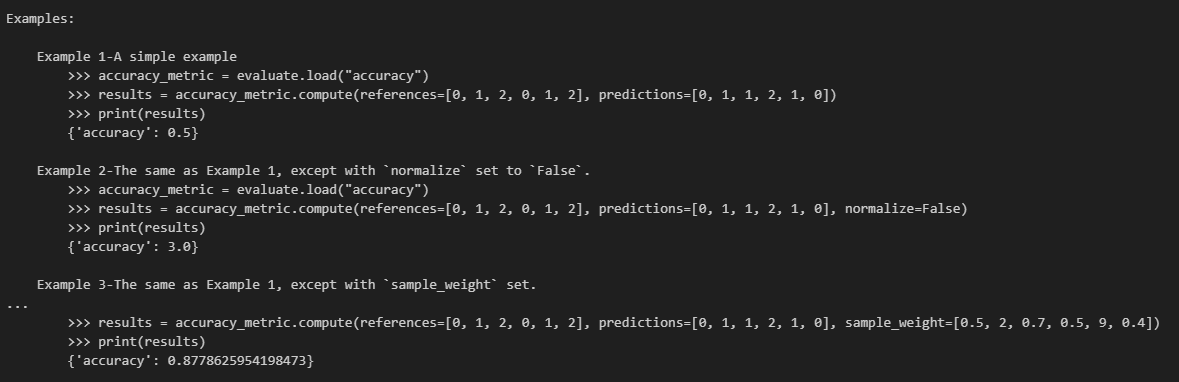
如果要更进一步知道这个评估函数的输入如何构造,可以查看input_description,他会更加详细地说明函数的参数说明,并且给出具体的示例。当然在jupyter里直接打印accuracy也是同样的效果。
评估指标计算
全局计算
把reference放一个list,prediction放一个list,然后整体做比对。这个例子的results={'accuracy':
0.5}。
1 2 accuracy = evaluate.load("accuracy" )0 , 1 , 2 , 0 , 1 , 2 ], predictions=[0 , 1 , 1 , 2 , 1 , 0 ])
迭代计算
对于单条数据,可以使用accuracy.add(),这里面放一对label,即一个refer和对应predict的label。
1 2 3 4 accuracy = evaluate.load("accuracy" )for ref, pred in zip ([0 ,1 ,0 ,1 ], [1 ,0 ,0 ,1 ]):
对于batch数据,使用accuracy.add_batch()进行计算,此时里面放的是n组label,一个refer和一个predict为一组([0,1],[0,1]是一组refer+predict,[1,0],[0,1]是另一组)。
1 2 3 4 accuracy = evaluate.load("accuracy" )for refs, preds in zip ([[0 ,1 ],[0 ,1 ]], [[1 ,0 ],[0 ,1 ]]):
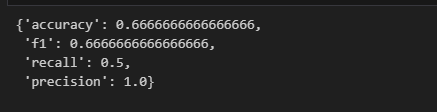
多个指标联合计算
想要同时计算多个评估指标,可以分别计算评估指标,而后更新整合到一个字典。还可以使用evaluate.combine()进行更便捷的联合计算,只需传入要计算的评估函数。
1 2 clf_metrics = evaluate.combine(["accuracy" , "f1" , "recall" , "precision" ])0 , 1 , 0 ], references=[0 , 1 , 1 ])
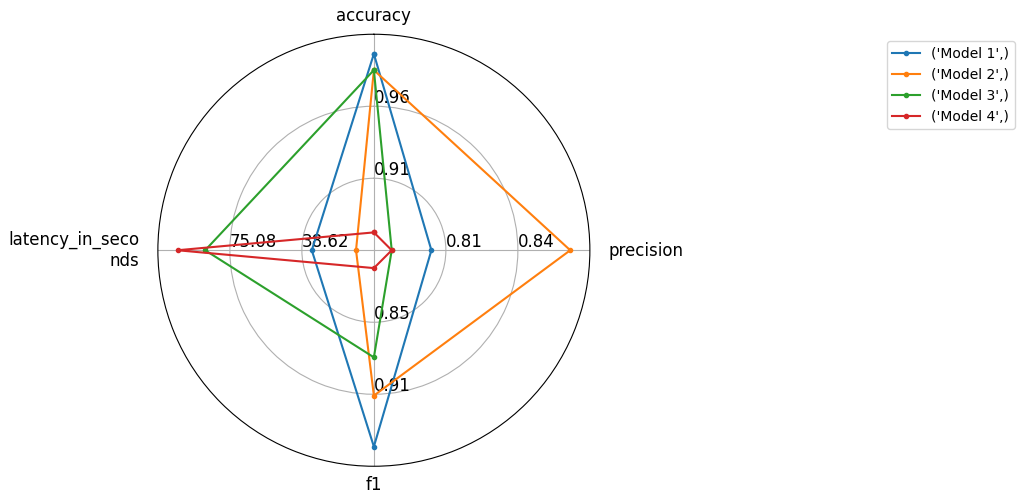
评估结果对比可视化
目前只提供了雷达图的方式对不同模型的结果进行可视化对比。
1 2 3 4 5 6 7 8 9 10 11 from evaluate.visualization import radar_plot "accuracy" : 0.99 , "precision" : 0.8 , "f1" : 0.95 , "latency_in_seconds" : 33.6 },"accuracy" : 0.98 , "precision" : 0.87 , "f1" : 0.91 , "latency_in_seconds" : 11.2 },"accuracy" : 0.98 , "precision" : 0.78 , "f1" : 0.88 , "latency_in_seconds" : 87.6 }, "accuracy" : 0.88 , "precision" : 0.78 , "f1" : 0.81 , "latency_in_seconds" : 101.6 }"Model 1" , "Model 2" , "Model 3" , "Model 4" ]
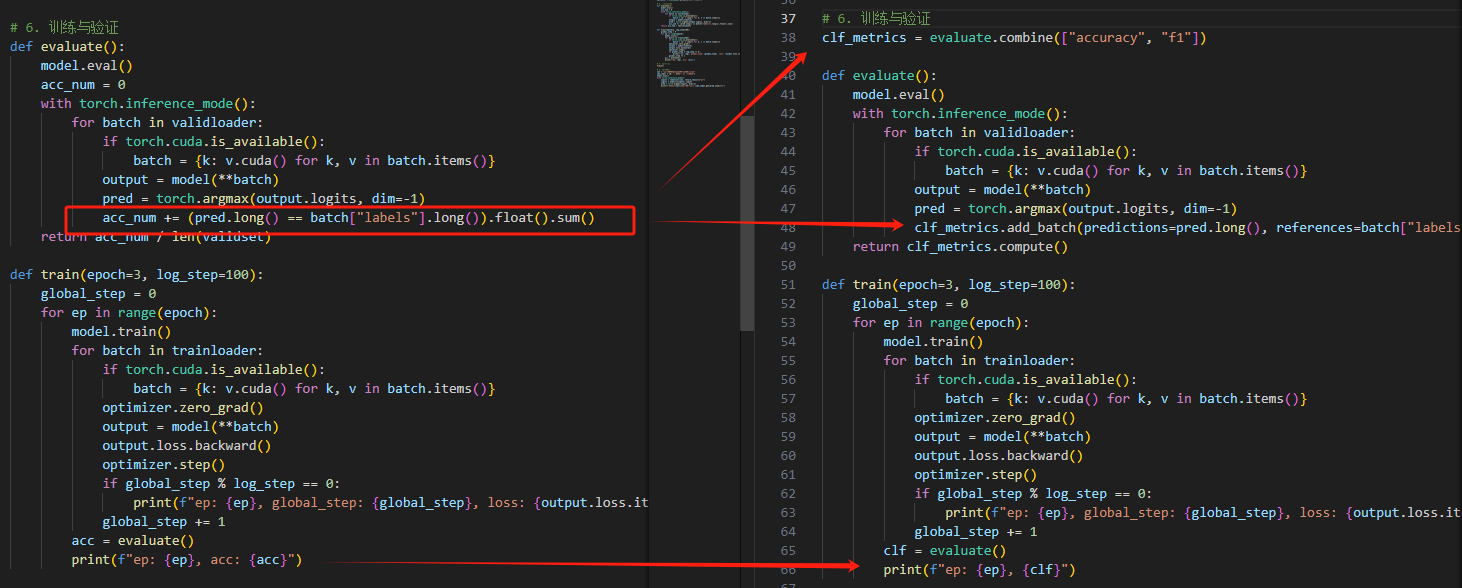
【文本分类代码优化】
对于Model章给出的文本分类代码的第六步进行优化。
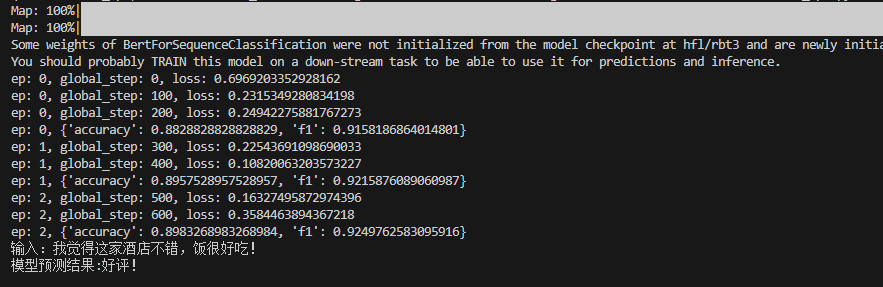
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import evaluate"accuracy" , "f1" ])def evaluate ():eval ()with torch.inference_mode():for batch in validloader:if torch.cuda.is_available():for k, v in batch.items()}1 )"labels" ].long())return clf_metrics.compute()def train (epoch=3 , log_step=100 ):0 for ep in range (epoch):for batch in trainloader:if torch.cuda.is_available():for k, v in batch.items()}if global_step % log_step == 0 :print (f"ep: {ep} , global_step: {global_step} , loss: {output.loss.item()} " )1 print (f"ep: {ep} , {clf} " )
多分类任务中如果想联合计算metric里的accuracy和f1,需要指定average这个参数,下面的方式是行不通的。
1 clf_metrics = evaluate.combine(["accuracy" ,"f1" ])
可以通过这个方式解决:
1 2 acc_metric = evaluate.load("accuracy" )"f1" )
关于一些metric的计算方式和关系可以参考这篇内容 。
 如果要看每个任务对应的评估指标,可以去huggingface的task面板查看。选择相应的任务后,huggingface会提供一个demo,以及适合这个任务的models、datasets和metrics。
如果要看每个任务对应的评估指标,可以去huggingface的task面板查看。选择相应的任务后,huggingface会提供一个demo,以及适合这个任务的models、datasets和metrics。