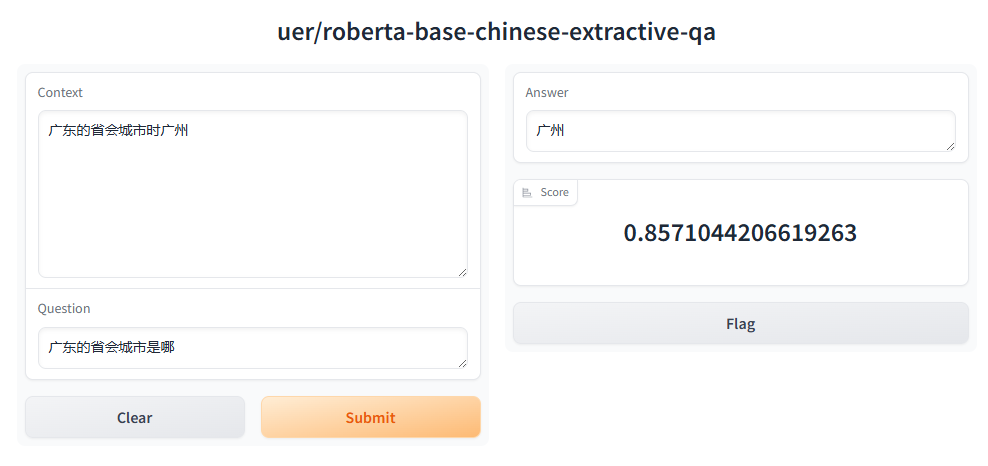
HuggingFace Transformers 基础知识与环境安装
创建虚拟环境
直接去官网安装anaconda,打开Anaconda Prompt。

使用conda命令新建一个虚拟环境transformers,中间的y/n输入y就行。
1 | |

安装好了之后激活环境,括号里的字变成创建的环境名则成功激活。
1 | |
推荐换一下默认源,换成清华的pypi镜像,下载速度会快很多。
1 | |
安装pytorch

正常步骤
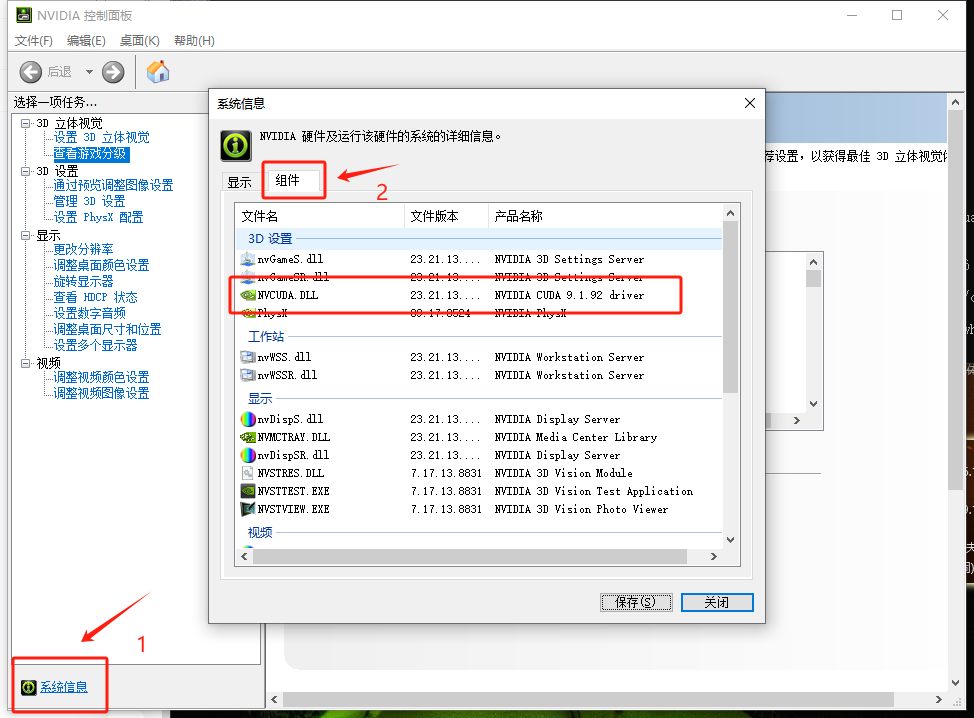
安装pytorch,鼠标右键选择NVIDIA控制面板,点击系统信息->组件查看NVIDIA cuda版本。
到pytorch官网按照自己的cuda版本,安装比cuda低版本的pytorch版本,推荐使用pip进行安装。

如果想装pytorch以前的版本在这:https://pytorch.org/get-started/previous-versions/,找对应版本的命令。
我电脑驱动太老了,直接装的cpu版本。
1 | |
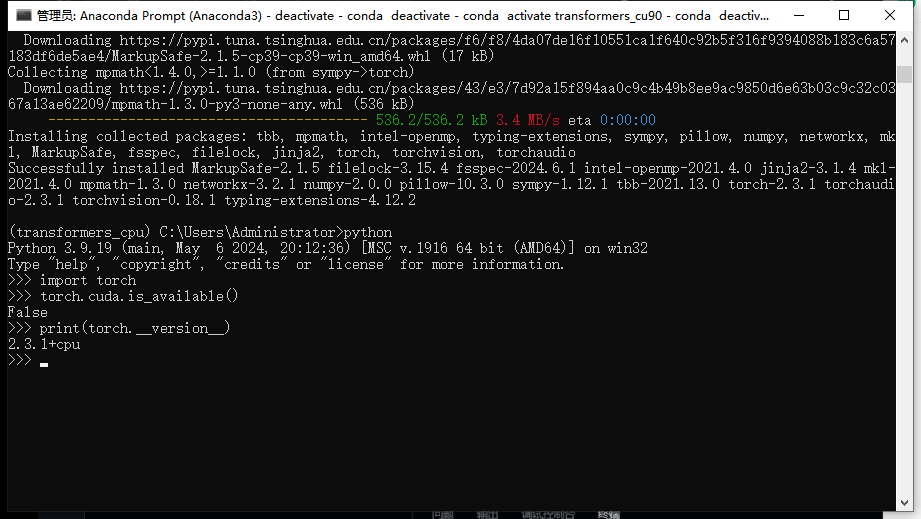
安装完成后,依次输入以下命令,返回True则安装成功:
import torchtorch.cuda.is_available()print(torch.__version__)
因为我装的是cpu版本,所以返回的是False。
踩坑【未解决】
因为我的cuda是9.1,最开始想安装的是cu9.0版本的,对应版本是torch-0.4.1,但这个版本太老了踩了很多坑!!!记录一下装torch-0.4.1的全过程。
安装网址:https://pytorch.org/get-started/previous-versions/,下载对应文件到本地。
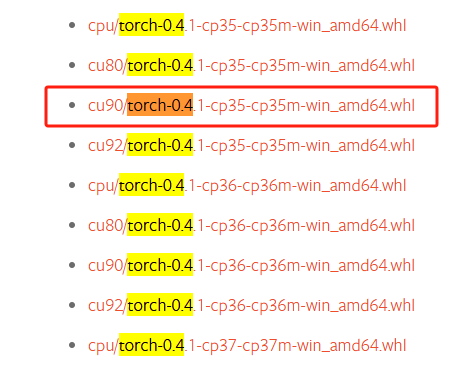
然后pip install+下载路径,会提示error,说没有whl。

找了很久,看到这篇博客,按照里面的方法解决了这个报错。总结如下:
- 进入下载目录,我这里下载路径是C:;
- 输入命令
pip debug --verbose;
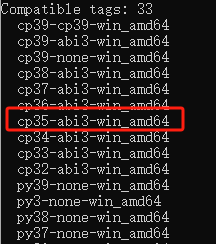
- 我原本下载文件的名字是torch-0.4.1-cp35-cp35m-win_amd64,那么找到对应的将文件名修改为torch-0.4.1-cp35-abi3-win_amd64a。
pip install torch-0.4.1-cp35-abi3-win_amd64.whl,安装成功。

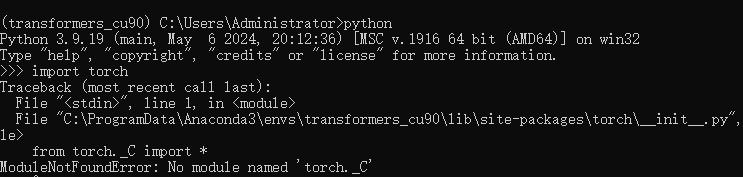
结果到import torch的时候直接找不到torch,没找到解决办法......
安装vscode
pycharm只有专业版才能写jupyter notebook,所以这里选择vscode。
官网安装vscode,下载一些必要插件:Python、Remote-ssh(远程连服务器)、Chinese Language Pack(汉化包)、Jupyter等。
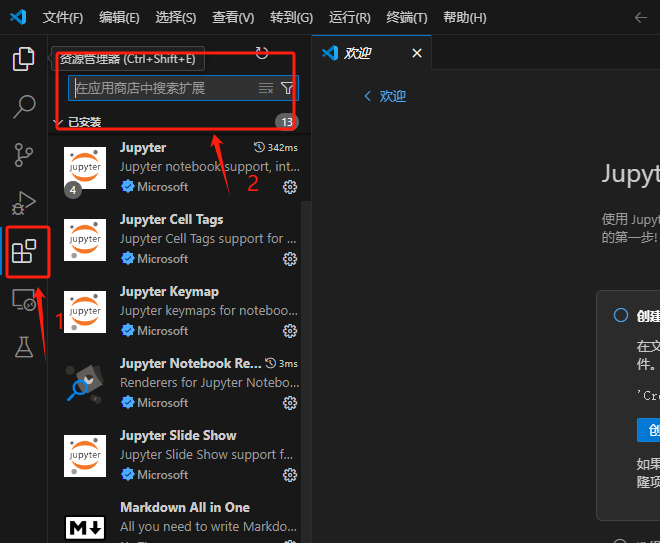
设置终端,vscode默认终端是powershell,改成cmd更方便。调出终端的快捷键是 ctrl+` 。
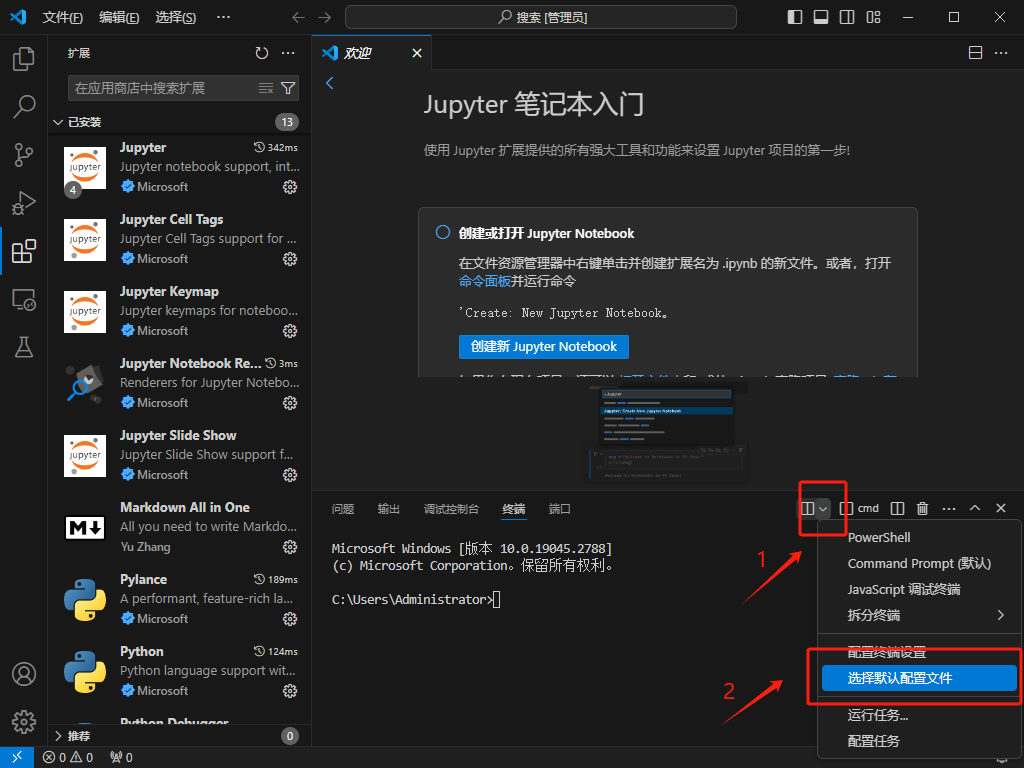
重新打开vscode后配置生效。
安装transformers
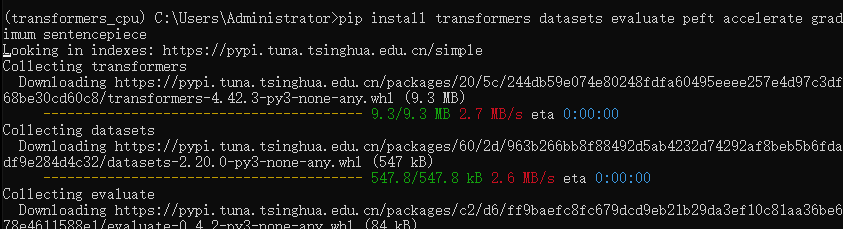
安装transfomers的基本库。
1 | |
1 | |
- Transformers:核心库,模型加载,模型训练,流水线等
- Tokenizer:分词器,对数据进行预处理,文本到token序列的互相转换
- Datasets:数据集库,提供了数据集的加载,处理等方法
- Evaluate:评估函数,提供各种评价指标的计算函数
- PEFT:高效微调模型的库,提供了几种高效微调的方法,小参数量撬动大模型
- Accelerate:分布式训练,提供了分布式训练解决方案,包括大模型的加载与推理解决方案
- Optimum:优化加速库,支持多种后端,如onnxruntime,openvino等
- Gradio:可视化部署库,几行代码快速实现基于web交互的算法演示系统
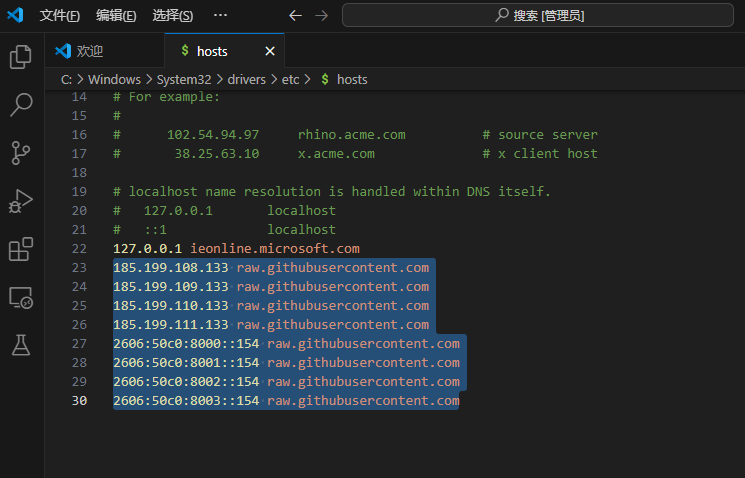
修改hosts文件,避免下载模型时可能出现的问题,文件路径C:\Windows\System32\drivers\etc\hosts。
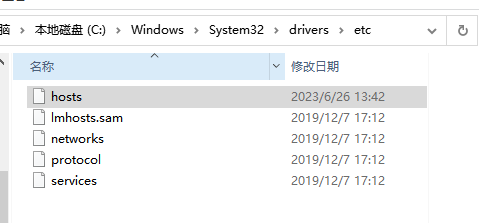
拷贝以下内容到hosts文件中,保存。
1 | |
环境配置完成。
进入vscode,创建一个juoyter demo,检查环境。
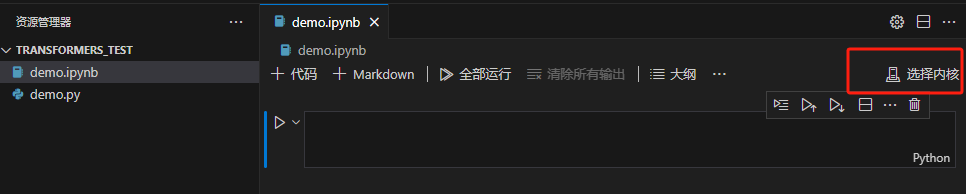
选择刚刚配置好的transformers_cpu的环境。
运行示例代码from transformers import *。
第一次运行时有报错,提示版本不兼容,大概率是scipy和numpy库的版本不兼容,scipy的版本兼容numpy版本在 1.16.5 到 1.23.0 之间,我的numpy版本可以看到是2.0.0。

这时可以选择升级scipy或者降级numpy。我选的是前者,因为降级numpy报了一大堆错误orz。
1 | |
成功解决,环境配置完成!
简单实例
先配置好python解释器的环境,选择transformers_cpu。
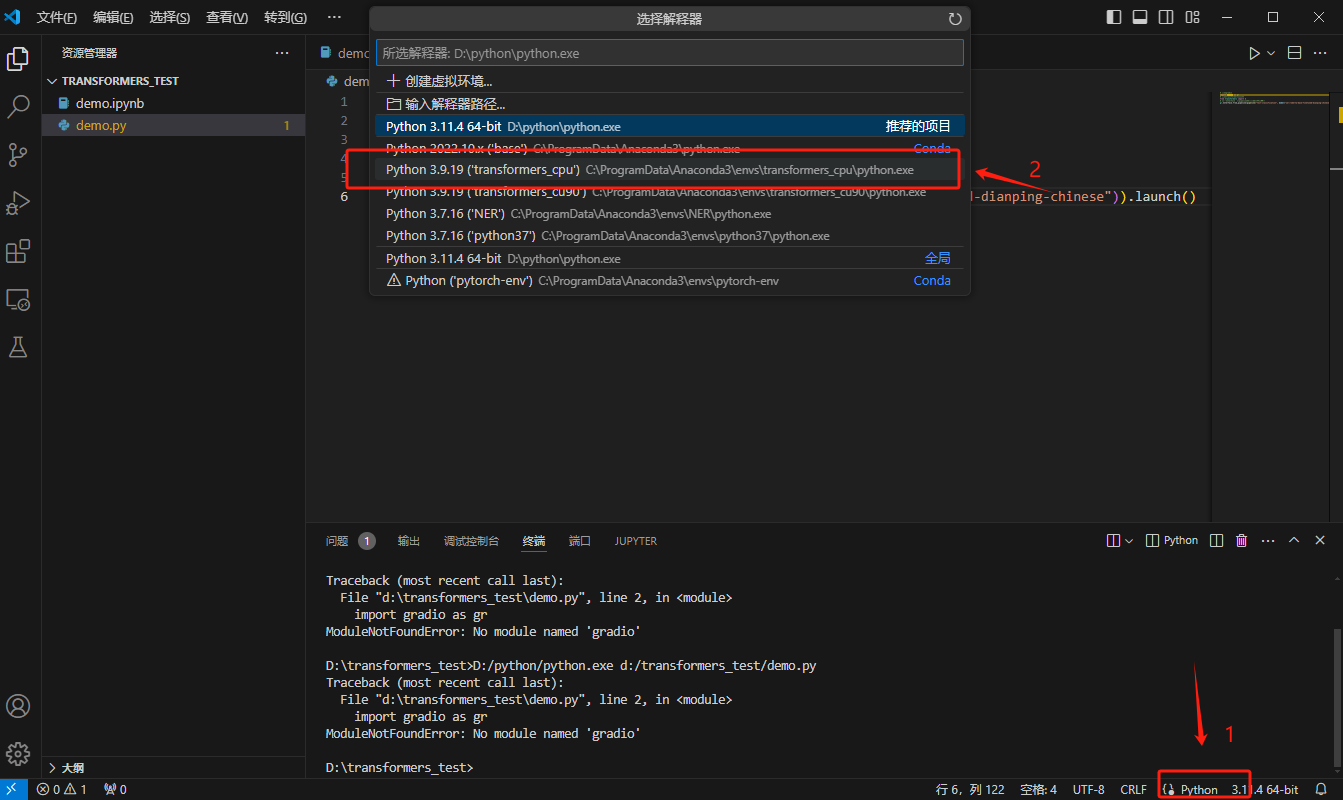
文本分类
1 | |
运行代码,可以看到在下载对应的模型,默认下载路径C:\Users\Administrator\.cache\huggingface\hub\。

可以在调用from_pretrained函数时使用cache_dir入参,指定缓存文件夹名。
1 | |
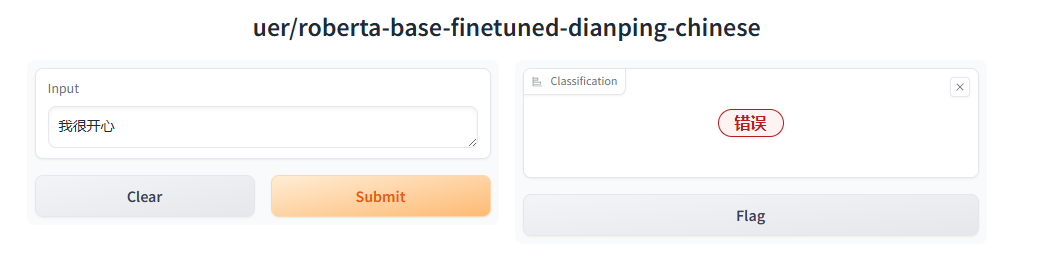
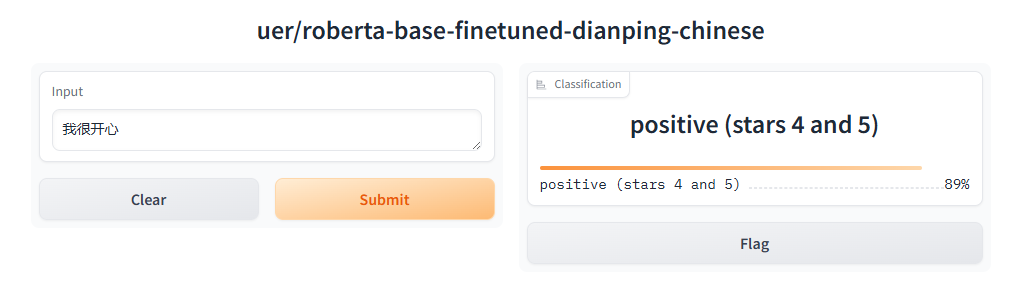
下载完成后,点击这个连接,访问文本分类模型。
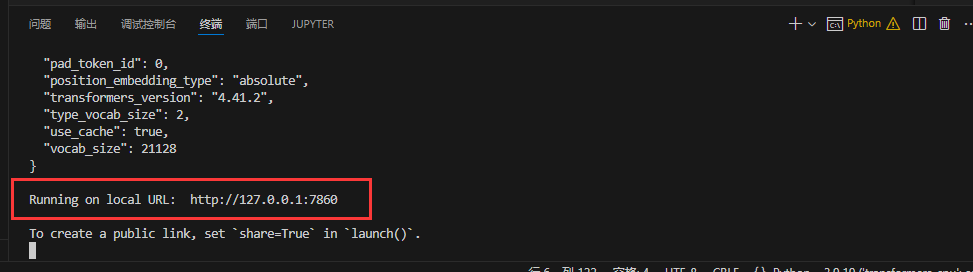
但是有报错,查了一下应该还是numpy版本的问题,还是太高了,所以需要降级numpy。
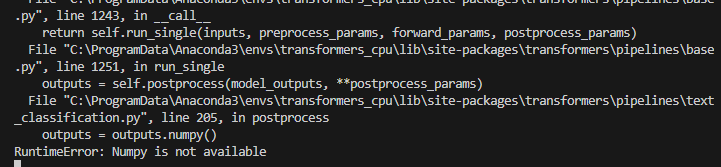
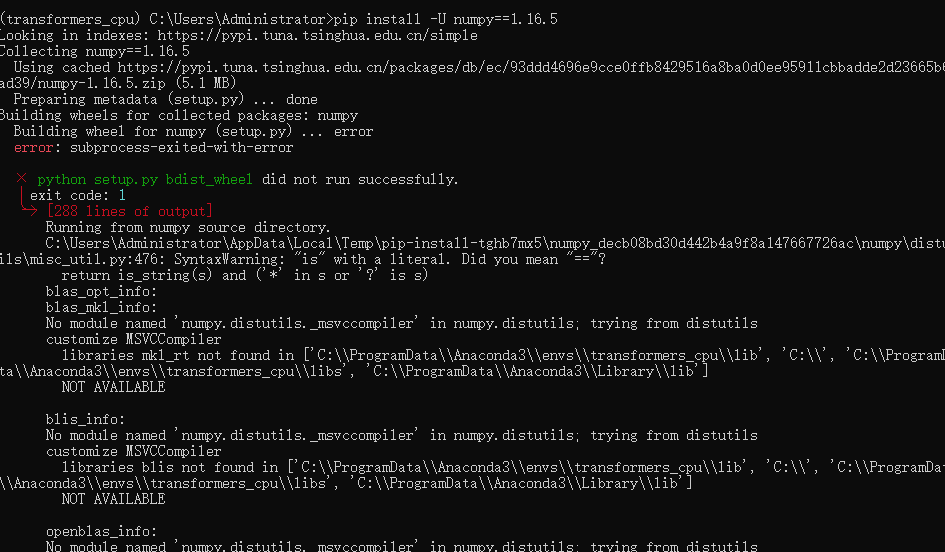
pip install -U numpy==1.16.5,报了一大堆错……
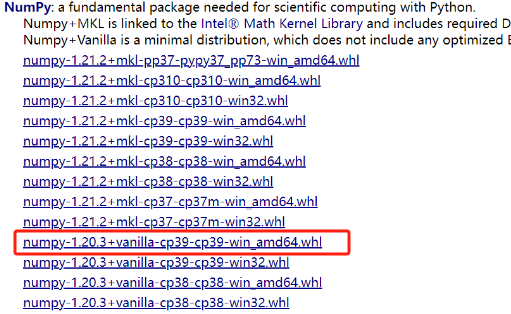
pip install -U numpy==1.20.3,查了下python3.9对应的numpy版本时1.20.3,试了一下,这次装成功了,但还是报错。
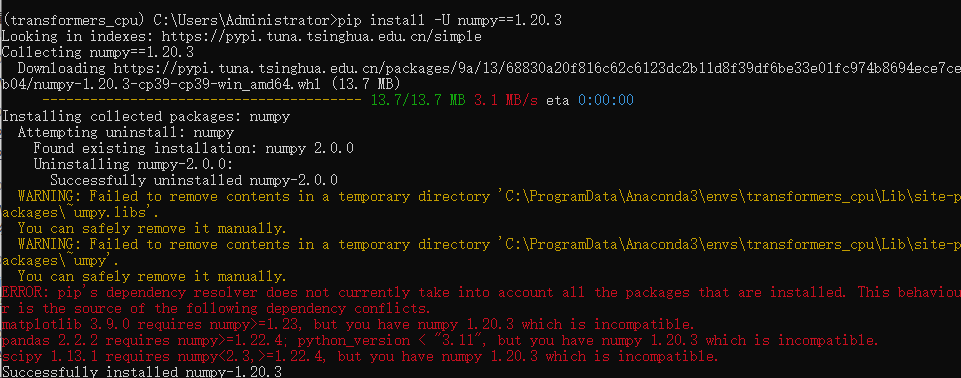
matplotlib 3.9.0需要numpy>=1.23,pandas
2.2.2需要numpy>=1.22.4,scipy
1.13.1需要2.3>numpy>=1.22.4。尝试安装1.23.0,pip install -U numpy==1.23.0,没报错!
重新运行代码,成功了!!!!
阅读理解
1 | |
有了之前的经验,第二个实例就很顺利了!