HuggingFace Transformers 基础组件之Datasets
Datasets基本使用
Huggingface Transformers提供的Datasets库可以很方便的加载本地或者Huggingface官网提供的数据集。
远程加载数据集
1 | |
- 在线加载:直接输入想要加载的在线模型在官网中的名字,可以看到是一个DatasetDict类,里面包括训练集和验证集的信息,
features可以直观的理解为csv的表头,num_rows是数据数量。
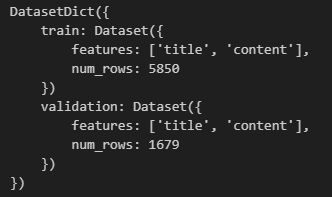
- 加载数据合集中的子任务:有的数据集(比如glue)包括很多的下游任务数据集,如果我们只想加载其中一个子任务的数据集,需要传入第二个参数,即子任务的名字,这里是"boolq"。之前提到过,
trust_remote_code=True意味着信任从远程下载的配置文件。
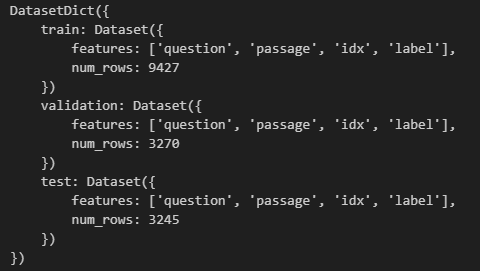
- 按数据集划分进行加载:
split参数允许加载切割后的数据集。比如,可以只加载训练集train,也可以指定要加载的数据比例。"train[10:100]"是加载索引10-100的训练集数据,"train[:50%]"是加载训练集后50%的数据。"train[:50%]", "validation[50%:]"代表着分开加载,先加载训练集后50%的数据,再加载验证集前50%的数据,可以看到此时的返回的是list。
!["train[:50%]", "validation[50%:]"](/images/05-基础组件之Datasets/image-20240731223909620.png)
查看数据集
1 | |
取出第一条数据、前两条数据、前五条数据的title。

还可以查看数据集的表头、数据属性等。


数据集划分
可以通过train_test_split()来划分测试集,test_size用于指定数据比例,这里指定test的比例为0.1。
1
2dataset = datasets["train"]
dataset.train_test_split(test_size=0.1)
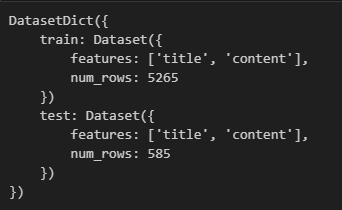
对于监督学习,如果希望划分后数据集label分布均匀,可以通过stratify_by_column指明标签所在的数据字段,保证划分出来的标签是均衡的。
1 | |
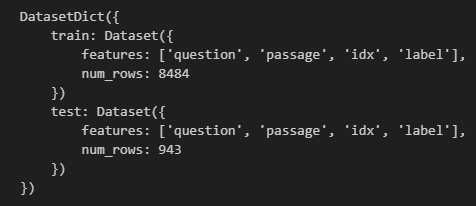
数据的选取与过滤
如果需要加载特定的数据,可以用select()根据数据索引进行选取,或者用filter()进行数据过滤,这就涉及到lambda函数。lambda的语法只包含一个语句,表现形式如下:lambda [arg1 [,arg2,.....argn]]:expression。其中,lambda
是 Python 预留的关键字,[arg…] 和 expression 由用户自定义。
1
2
3
4# 选取
datasets["train"].select([0, 1])
# 过滤:筛选出title中含有“中国”的数据
filter_dataset = datasets["train"].filter(lambda example: "中国" in example["title"])

lambda的常见用法如下:
- 赋值给变量:
add = lambda x, y: x+y,这里定义了一个加法函数,输入是x和y,输出是它们的积x+y。此时add指向具有加法功能的函数,add(1,2)=3;- 赋值给函数:
time.sleep=lambda x:None,将lambda函数赋值给其他函数,从而用lambda函数替换其他函数。此时执行time.sleep(3)后程序不会休眠3秒钟,因为lambda的输出是None;- 将lambda函数作为参数传递给其他函数,如map、reduce、sorted、filter等。
数据映射
定义一个函数后,如果希望对每条数据都应用这个函数,要用到map()方法。一个简单的方式是将函数名作为map的参数传入。
1 | |

更为复杂的一个使用方式是结合tokenizer做数据处理。这里定义一个数据处理的函数,对模型的输入(title和content)进行分词。
1 | |
将这个函数映射到整个数据集上,得到以下结果。可以看到此时的数据集多了几个字段,其实就是label(titile的编码结果)以及tokenizer返回的input_ids、token_type_ids和attention_mask(详见tokenizer)。
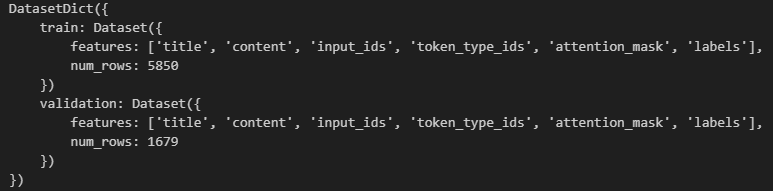
此外,map()还支持batch和多线程处理数据,使用num_proc可以指定线程的数量。要注意的是,如果选择多线程处理,那么tokenizer要作为一个参数传给数据处理的函数,因为线程之间资源是不共享的,所以在调用函数时要将tokenizer传给每个线程。
1 | |
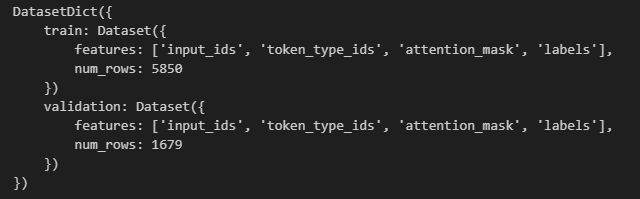
数据处理后,如果不需要原始字段,可以使用map()自带的参数remove_columns移除原始数据集的字段。
1
processed_datasets = datasets.map(preprocess_function, batched=True, remove_columns=datasets["train"].column_names)
保存与加载
处理完数据后,save_to_disk()用于保存处理后的数据到本地,load_from_disk()用于从本地加载数据。
1
2
3
4# 数据保存
processed_datasets.save_to_disk("./processed_data")
# 数据加载
processed_datasets = load_from_disk("./processed_data")
加载本地数据集
直接加载文件
与远程加载数据相比,load_dataset()内需要指定加载的数据集类型、路径等。
1
dataset = load_dataset("csv", data_files="./ChnSentiCorp_htl_all.csv", split="train")load_dataset(),Dataset里的from_csv()也可以用来加载csv文件。
1
dataset = Dataset.from_csv("ChnSentiCorp_htl_all.csv")
加载文件夹内的文件
使用data_dir="path"指定文件夹路径,即可加载该文件夹内的所有文件作为dataset。如果是加载文件夹内的指定文件,则通过data_files=["a1_path","a2_path"]指明要加载的文件路径。
1 | |
通过预先加载的其他格式转换加载数据集
通过pandas读取数据后,可以使用Dataset.from_pandas()将数据转化为Dataset类。
1 | |
Dataset还提供了很多其他格式数据的转换方式,如json、dict等。

需要注意的是,在加载list数据时,需要明确数据字段,否则会报错,因为Dataset中的feature就是数据集中的字段,需要根据字段名去读取该字段下的数据。
1 | |
配合自定义脚本加载数据集
有时数据集格式复杂,需要配合自定义脚本进行数据集加载。以问答数据集cmrc2018_trial为例。

采用直接加载的方式。
1 | |
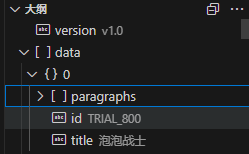
可以看到,如果直接加载数据是读取不全的。它只读取到了paragraphs、id和title字段,paragraphs里有多个字段被忽略了,id、context以及qas里的question、answers这种嵌套在里面的数据都没有读到。(这里field用于指明数据存放在data字段里)

为了将数据读全,需要配合自定义脚本进行数据读取。主要实现三个方法:_info用于定义字段的数据类型,_split_generators用于指定数据集路径和数据集划分,_generate_examples用于数据处理。up的脚本可以在github上找到。
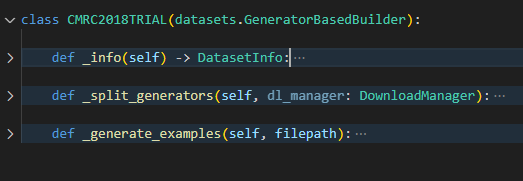 配合自定义脚本加载数据,得到想要的结果。
配合自定义脚本加载数据,得到想要的结果。
1 | |
【文本分类代码优化】
上一章的文本分类示例在进行数据加载的时候,写了一个数据聚合函数传给DataLoader,其实Dataset提供了一些简单格式数据处理下预制好的DataCollator。以最简单的DataCollatorWithPadding为例,对上一章给出的文本分类代码进行优化(主要是步骤1~4的优化)。
- 可是使用
filter搭配lambda进行数据过滤; - 通过
map将数据处理函数映射到每条数据上; - 使用
DataCollatorWithPadding作为聚合函数,这里需要注意的是,如果有自定义的数据字段(也就是除了input_ids, token_type_ids, attention_mask, labels以外的字段),是无法使用官方提供的DataCollator进行padding和数据聚合的。
使用huggingface的Dataset加载数据集,用tokenizer对文本数据进行编码后,此时的特征数据还不是tensor,需要转换为深度学习框架所需的tensor类型。data_collator的作用就是将features特征数据转换为tensor类型的dataset。
1 | |