Python nlp 简单的数据处理
简单字符串处理
去除与替换
strip()
strip()用于去除首lstrip()尾rstrip()的字符,若括号内为空则默认去除空格。
- 若是单个字符,则是从首/尾字母开始匹配要去除的内容,到第一个匹配失败停止。

- 若是多个字符,去除字符时与括号内的字符顺序无关。

replace()
replace()需要两个参数,一个是要被替换的字符,另一个是用于替换的字符。(即替换前和替换后)

查找与判断
find()
find()会返回要目标字符的索引(从0开始)。

isXXX()
python官方定义的字母是英文字母+汉字;官方定义的数字是阿拉伯数字+带圈的数字。


分割与合并
split()
split()根据传入的分割字符进行分割,返回一个list。

join()
join()以指定的字符进行字符串合并,在分割符相同的情况下和split()为互逆操作。

正则表达式
匹配方法
match():从开始位置进行匹配,开头没有返回NoneType不会继续往后搜索,返回MatchObject;search():开头不匹配则会跳过开头继续查找,返回MatchObject;findall():搜索整个字符串,返回一个list。字符匹配
正则表达式是一个字符一个字符匹配的,用pattern存储“规则”(或者说是模板)。
| 说明 | 示例 | 匹配结果 | |
|---|---|---|---|
一般字符 |
匹配字符本身 | abc | abc |
. |
匹配除了换行符外的任意一个字符 | a.c | abc, adc, a/c |
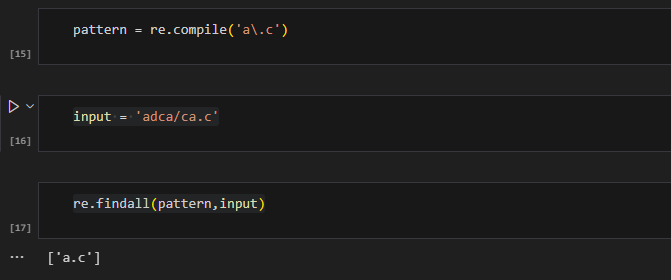
\\ |
匹配有特殊作用的字符,如 . 或 * | a\.c | a.c |
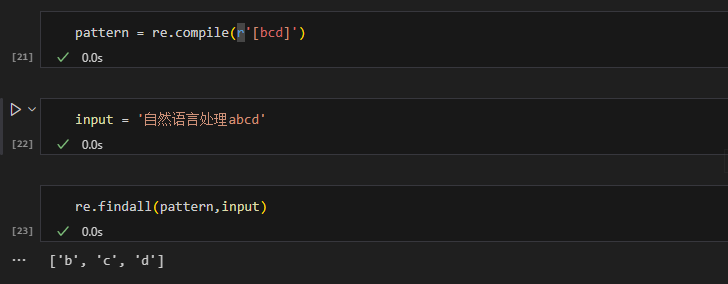
[...] |
匹配中括号内的任意一个字符 | a[bcd]e | abe, ace, ade |
.

\
[...]
[abc]:匹配字符集里的字符;[a-zA-Z]:匹配所有英文字母不区分大小写;[^a-zA-Z]:^表示对当前正则表达式取否,即匹配不是英文字母的字符;|:可以连接两个规则,如[a-zA-Z]|[0-9]=[a-zA-Z0-9]。

预定义字符集
\大写字母是\小写字母的否定。
\d, \D:数字与非数字;\s, \S:空白字符(间隔符)[<空格>\t\r\n\f\v]与非空白字符;\w, \W:单词字符[A-Za-z0-9_]与非单词字符;\b:\w能匹配的到的字符的边界,具体可参考这篇博客,部分例子如下。

数量词
| 说明 | 示例 | 匹配结果 | |
|---|---|---|---|
* |
匹配前一个字符[0, ∞)次 | abc* | ab, abccc |
+ |
匹配前一个字符[1, ∞)次 | abc+ | abc, abccc |
? |
匹配前一个字符[0, 1)次 | abc? | ab, abc |
{m} |
匹配前一个字符m次 | abc{3} | abccc |
{m,n} |
匹配前一个字符[m, n]次 | ab{1,2}c | anc, abbc |
字符串的替换和修改
sub(rule, replace, target[,count]):第一个参数是正则表达式,第二个参数指定用于替换的字符串,第三个参数是要被替换处理的字符串,第四个参数是最多替换次数。subn(rule, replace, target[,count]):参数说明同上,不同的是,sub()返回一个被替换后的字符串,subn()返回的是一个元组,第一个元素是替换后的字符串,第二个元素是产生替换的次数。
re+split()
使用指定的正则规则在目标字符串中查找匹配的字符串,并以此为界进行分割。
(?P<...>)
(?P<name>)允许给不同的规则取名,通过名字来决定使用哪个规则。
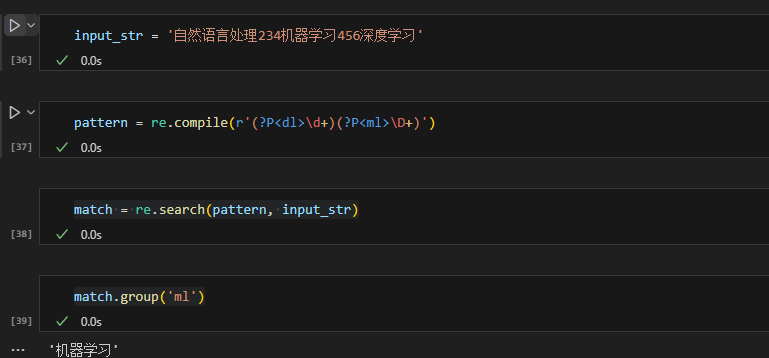 需要注意的是,这里使用search匹配到的第一个结果是“机器学习”而非“自然语言处理”。这是因为使用命名组时,search先匹配的是符合两个规则的子串,然后在这个子串中进行匹配。在这个例子中,第一个被找到的匹配整个正则表达式的子串是“234机器学习”,所以,没有“自然语言处理”。如果要匹配数字之前的文本,要调换两个组的顺序。
需要注意的是,这里使用search匹配到的第一个结果是“机器学习”而非“自然语言处理”。这是因为使用命名组时,search先匹配的是符合两个规则的子串,然后在这个子串中进行匹配。在这个例子中,第一个被找到的匹配整个正则表达式的子串是“234机器学习”,所以,没有“自然语言处理”。如果要匹配数字之前的文本,要调换两个组的顺序。

NLTK
适用于英文文本的处理。pip install nltk
分词
英文分词的时候token是不区分大小写的。
1 | |
Text对象
Text类里封装了很多方法。 1
2
3
4
5
6
7
8from nltk.text import Text
input_str = "Today's weather is good, very windy and sunny, we have no classes in the afternoon,We have to play basketball tomorrow."
tokens = word_tokenize(input_str)
t = Text(tokens)
t.count('good') # 统计 good 的出现次数
t.index('good') # 获取 good 的索引
t.plot(8) # 将出现频率前八的单词可视化

停用词过滤
停用词即在句子中权重低的词(非关键词),如is/the/we/their等,这些出现频率太高、不包含重要语义的词。
1
2
3
4
5
6
7
8
9
10
11
12
13
14from nltk.corpus import stopwords
input_str = "Today's weather is good, very windy and sunny, we have no classes in the afternoon,We have to play basketball tomorrow."
tokens = word_tokenize(input_str)
test_words = [word.lower() for word in tokens]
# 将分词后的结果变为无重复元素的集合
test_words_set = set(test_words)
# 查看 test_words_set 有的停用词
test_words_set.intersection(set(stopwords.words('english')))
# 过滤停用词
filtered = [w for w in test_words_set if(w not in stopwords.words('english'))]
# 输出结果
# ['today', 'good', 'windy', 'sunny', 'afternoon', 'play', 'basketball', 'tomorrow', 'weather', 'classes', ',', '.', "'s"]
词性标注
标注后的词性可以参考这里给出的解释。
1 | |

| POS Tag | 指代 |
|---|---|
| CC | 并列连词 |
| CD | 基数词 |
| DT | 限定符 |
| EX | 存在词 |
| FW | 外来词 |
| IN | 介词或从属连词 |
| JJ | 形容词 |
| JJR | 比较级的形容词 |
| JJS | 最高级的形容词 |
| LS | 列表项标记 |
| MD | 情态动词 |
| NN | 名词单数 |
| NNS | 名词复数 |
| NNP | 专有名词 |
| PDT | 前置限定词 |
| POS | 所有格结尾 |
| PRP | 人称代词 |
| PRP$ | 所有格代词 |
| RB | 副词 |
| RBR | 副词比较级 |
| RBS | 副词最高级 |
| RP | 小品词 |
| UH | 感叹词 |
| VB | 动词原型 |
| VBD | 动词过去式 |
| VBG | 动名词或现在分词 |
| VBN | 动词过去分词 |
| VBP | 非第三人称单数的现在时 |
| VBZ | 第三人称单数的现在时 |
| WDT | 以wh开头的限定词 |
分块
1 | |
命名实体识别
1 | |
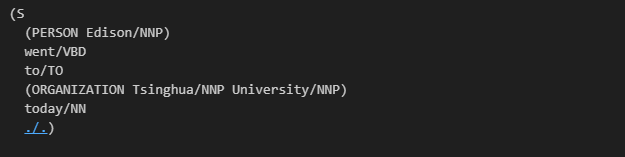
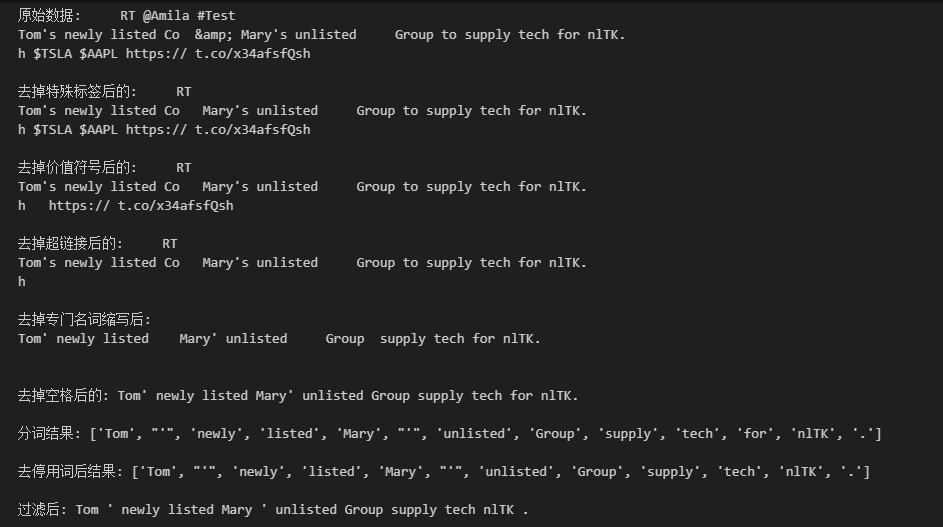
数据清洗实例
1 | |
Spacy
pip install spacy &
python -m spacy download en
1 | |
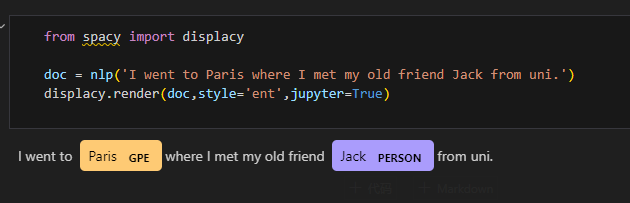
spacy提供实体标注可视化包displacy。
jieba
jieba分词综合了基于字符串匹配的算法和基于统计的算法。
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG);
- 采用了动态规划查找最大概率路径,找出基于词频的最大切分组合;
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
分词
jieba分词时可选择4种模式:精确模式、全模式、搜索引擎模式、paddle模式,最常用的还是前三种。
jieba.cut 以及 jieba.cut_for_search
返回的结构都是一个可迭代的 generator,可以使用 for
循环来获得分词后得到的每一个词语(unicode),jieba.lcut 以及
jieba.lcut_for_search 直接返回 list。
jieba.cut方法接受四个输入参数:- 需要分词的字符串;
cut_all参数用来控制采用全模式/精确模式,默认是精确模式;HMM参数用来控制是否使用 HMM 模型;use_paddle参数用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,通过enable_paddle接口安装paddlepaddle-tiny,并且import相关代码;
jieba.cut_for_search方法接受两个参数:- 需要分词的字符串;
- 是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细。
1 | |
全模式:我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
精确模式:我/ 来到/ 北京/ 清华大学
新词识别:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
搜索引擎模式: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
添加自定义词典
对于一些专有名词,可以用jieba加载自定义词典(词典应保存为utf-8编码)。词典格式是一个词一行,每一行包括词语、词频(可省略)、词性(可省略)三部分,用空格隔开,顺序不可颠倒。
1 | |
也可以直接添加词,但这个词只是临时保存了,再创建新的文本分词时词表里不会有这个词。
1
jieba.add_word(word, freq=None, tag=None)
关键词抽取
analyse.extract_tags可以抽取文本里的关键词。
1
2
3
4
5import jieba.analyse
text = "故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等"
seg_list = jieba.cut(text, cut_all=False)
tags = jieba.analyse.extract_tags(text, topK=5)

withWeight可以查看每个词的权重,topK限定查看的范围。
1 | |

词性标注
1 | |
Reference:python-nlp(P2-P13),正则表达式-边界,jieba分词用法及原理