HuggingFace Transformers 基础组件之Tokenizer
Reference:【HuggingFace Transformers-入门篇】基础组件之Tokenizer,Huggingface NLP Course
Transformer 模型只接受张量作为输入。与其他神经网络一样,Transformer 模型不能直接处理原始文本,因此的第一步是将文本输入转换为模型可以理解的数字。为此,我们使用一个分词器tokenizer,它将负责:
- 将输入拆分为称为标记的单词、子单词或符号(如标点符号)
- 将每个标记映射到整数
- 添加可能对模型有用的其他输入

Tokenizer基本使用
我们可以直接给tokenizer传入句子,随后会得到一个字典,该字典可以提供给我们的模型。剩下唯一要做的就是将输入
ID 列表转换为张量。 
加载与保存
AutoTokenizer会根据传入的参数自动分配默认的tokenizer。加载的时候会用到from_pretrained()方法,即从预训练阶段开始加载。
1
2
3
4from transformers import AutoTokenizer
sen = "弱小的我也有大梦想!"
# 从HuggingFace加载,输入模型名称,即可加载对于的分词器
tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
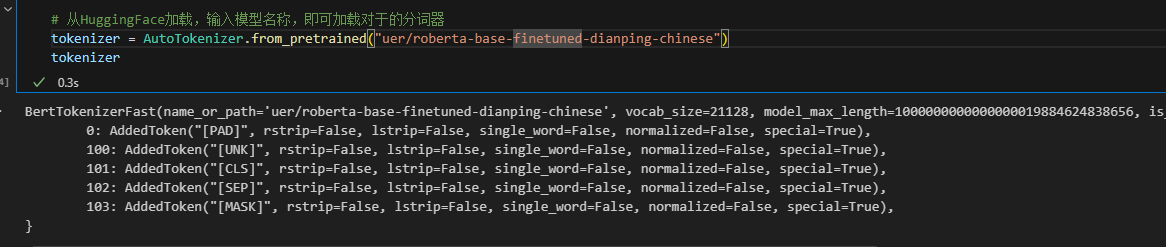
默认的下载路径是C:\Users\Administrator\.cache\huggingface\hub\,也可以指定路径存储。
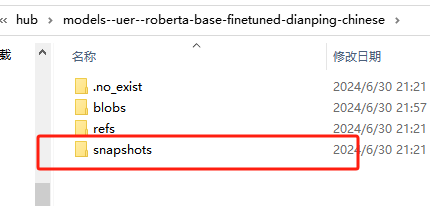
模型文件里面的snapshots文件夹里是模型有用的文件。
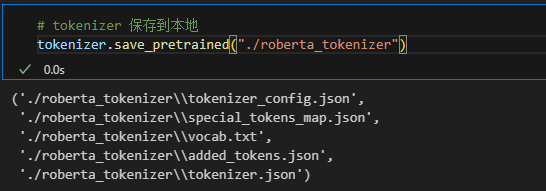
使用save_pretrained()方法来将tokenizer保存到指定路径。./roberta_tokenizer表示将路径设置为代码文件所在文件夹的roberta_tokenizer文件夹中。
1 | |
这里记一下从官方文档看到的两个英文词概念:
- Architecture: 模型的骨架,即模型中每个层和每个操作的定义。
- Checkpoints: 在给定架构中加载的权重。
例如,BERT是一个architecture,而 bert-base-cased(Google为 BERT 第一个版本训练的一组权重)则是一个checkpoint。
句子分词
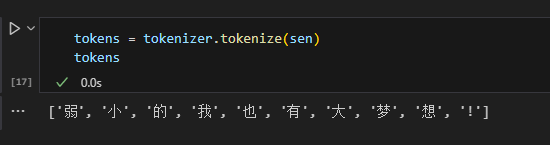
加载完tokenizer之后需要对句子进行分词,可以使用tokenize()方法。
1
tokens = tokenizer.tokenize(sen)
查看词典
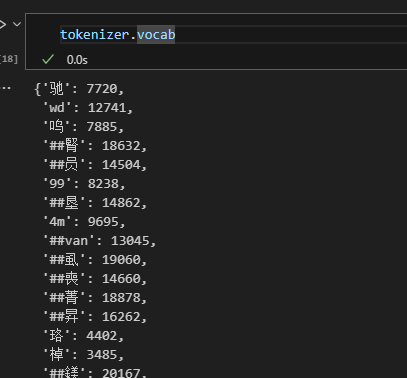
可以查看这个分词器的词典,井号我觉得可以理解为占位符,意思是这个字通常出现在一个词的第二个位置,也就是说比起这个字单独出现,它和其他字一起出现的概率更高,具体可以看搜搜subword的概念。
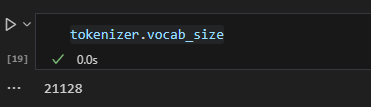
BERT的分词方式是WordPiece,词表的构造是基于subword(子词)的,有助于缓解OOV(Out of Vocabulary)问题,即测试集有很多模型训练时没见过的单词。
1 | |
索引转换
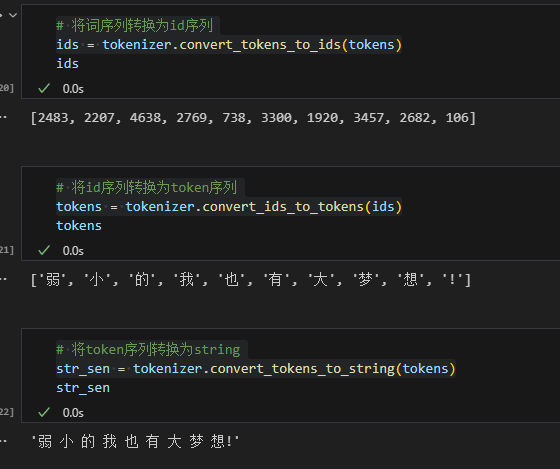
使用convert_tokens_to_ids()将分词后的token序列转换成id序列送入神经网络。
1
2
3
4
5
6# 将词序列转换为id序列
ids = tokenizer.convert_tokens_to_ids(tokens)
# 将id序列转换为token序列
tokens = tokenizer.convert_ids_to_tokens(ids)
# 将token序列转换为string
str_sen = tokenizer.convert_tokens_to_string(tokens)
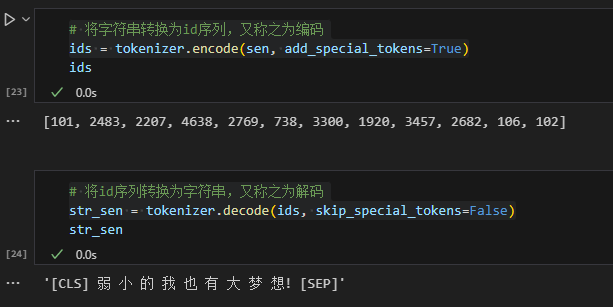
更简便的方法是使用encode()一步实现句子序列到id序列的转换。这里有两个参数,sen即输入的句子,add_special_tokens用来控制是否给id序列添加特殊符号。
在BERT的分词方法中,会在id序列的前后或者中间加入一些特殊符号,如这里的[CLS]和[SEP],前者代表一句话的开始,后者标志着一句话的结束。
1 | |
可以看到使用encode()方法会在句子前后多了101和102,其实就对应特殊符号[CLS]和[SEP],因为add_special_tokens=True,不添加的话可以设为False。同理,解码decode()也可以通过这个参数选择要不要将特殊符号及进行解码。
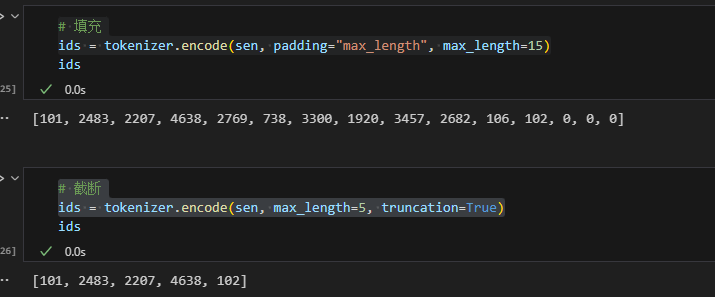
填充与截断
让模型处理大量数据时会涉及到数据的填充和截断,以统一每条数据长度。即短数据填充padding,长数据截断truncation。
1
2
3
4# 填充
ids = tokenizer.encode(sen, padding="max_length", max_length=15)
# 截断
ids = tokenizer.encode(sen, max_length=5, truncation=True)
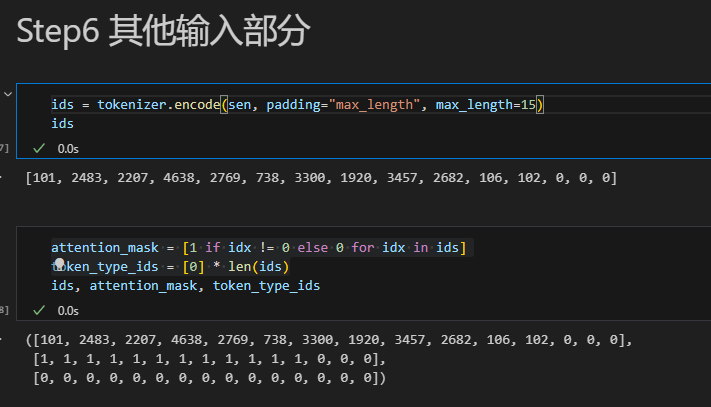
其他输入部分
因为存在填充,所以我们需要告诉模型哪些是填充的哪些是真实有效的输入,这就需要attention_mask。此外,对于BERT模型,它需要token_type_ids这个参数来区分哪些词属于第一句,哪些属于第二句,也就是段编码。
这是因为BERT的input由三部分组成,除了分词后的词向量(token embeddings),还有段编码(segment embeddings)和位置编码(Position Embedding),详见之前的PLMs的笔记。
1 | |
attention_mask就是id为0记为0否则记为1。由于这是一句话的句间文本,所以token_type_ids都是0,长度就是整个token的长度。
快速调用方式
Huggingface
Transformers提供了快捷调用方式,可以一步实现上述步骤,也就是encode_plus()方法。调用后返回一个dic,里面包含了id序列和attention_mask。除此之外,直接调用tokenizer(不是tokenize(),注意区分)也可以得到一样的效果。
1
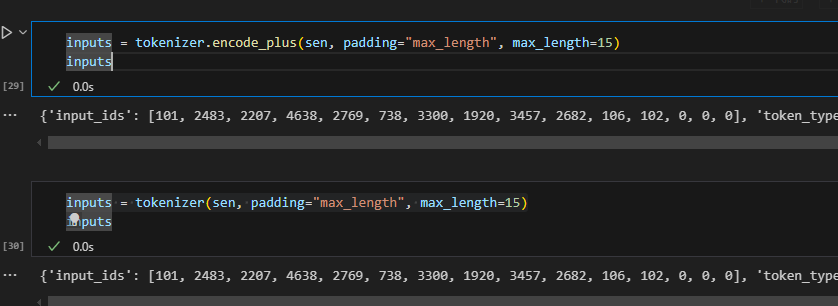
2inputs = tokenizer.encode_plus(sen, padding="max_length", max_length=15)
inputs = tokenizer(sen, padding="max_length", max_length=15)
处理batch数据
批量处理数据也可以用同样的方法,返回的值形如注释。 1
2
3
4
5
6
7
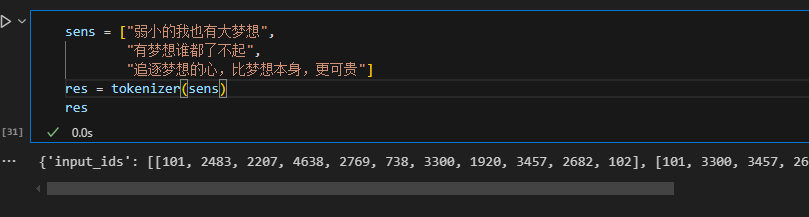
8sens = ["弱小的我也有大梦想",
"有梦想谁都了不起",
"追逐梦想的心,比梦想本身,更可贵"]
res = tokenizer(sens)
''' {'input_id' : [[..1..],[..2..],[..3..]],
'token_type_ids' : [[..1..],[..2..],[..3..]],
'attention_mask' : [[..1..],[..2..],[..3..]]} '''
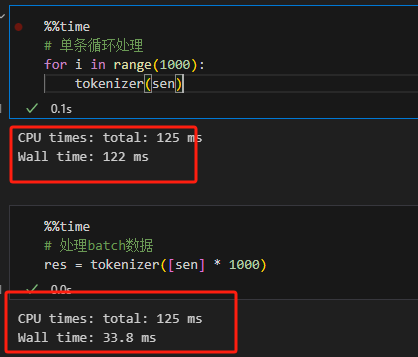
 对比for循环与batch处理的时间,可以发现batch明显快于循环计算。
对比for循环与batch处理的时间,可以发现batch明显快于循环计算。
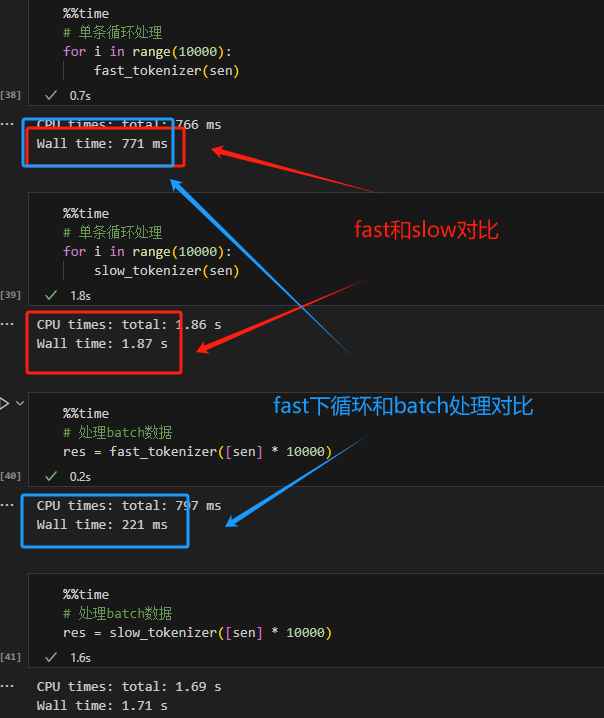
Fast/Slow Tokenizer
- FastTokenizer:基于Rust实现,速度块,有两个额外返回值
offsets_mapping、word_ids。 - SlowTokenizer:基于Python实现,速度较慢。
使用from_pretrained()方法分配tokenizer时默认分配FastTokenizer,如果要设置成SlowTokenizer需括号内增加参数use_fast=False。
1
2
3sen = "弱小的我也有大Dreaming!"
fast_tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
slow_tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese", use_fast=False)
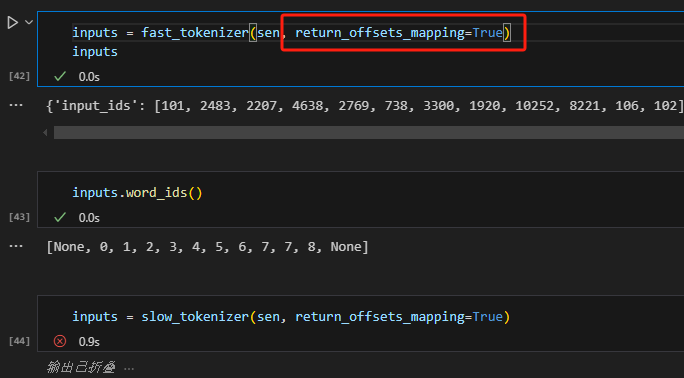
FastTokenizer有个额外返回值offsets_mapping,使用时将需要设置return_offsets_mapping=True。随之还会返回word_ids,这两个值相互对应。
1 | |
- sen = "弱小的我也有大Dreaming!"。
- 'offset_mapping': [(0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 12), (12, 15), (15, 16), (0, 0)]
- word_ids: [None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
word_ids会记录每个词在句子中的位置,None分别对应句首句尾的特殊字符[CLS]和[SEP],也就是offset_mapping里的(0,0)。(0,1)对应第一个字"弱"的位置,(6,7)对应第7个字"大"的位置。
因为截断,所以Dreaming被分为两个数据段,所以word_ids里有两个7,对应offset_mapping的(7,12)和(12,15),表示这两个部分合起来是一个完整的token。
 这里我还试了其他的例子:
这里我还试了其他的例子: 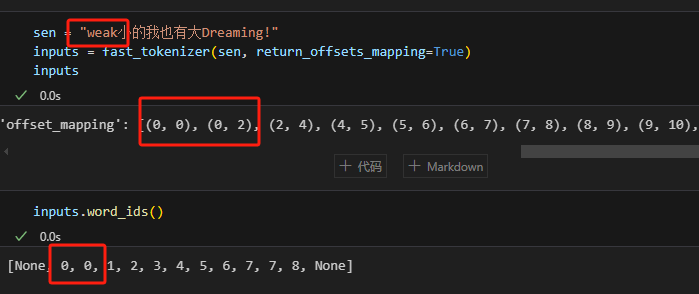 这个更多的会在QA中用到,因为回答问题时需要记录答案在原始文本中开始和结束的位置。
这个更多的会在QA中用到,因为回答问题时需要记录答案在原始文本中开始和结束的位置。
特定Tokenizer的加载
还可以加载特定模型的分词器(只要Huggingface
Model里有),比如这里想用天工的分词器。
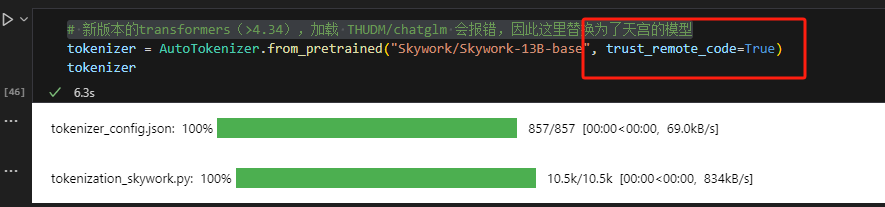
 找到模型名使用from_pretrained进行加载,加载时必须添加参数
找到模型名使用from_pretrained进行加载,加载时必须添加参数trust_remote_code=True,不然会报错。
1 | |
【代码汇总】
以换行为分割线,单独运行每块代码。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59from transformers import AutoTokenizer
sen = "弱小的我也有大梦想!"
# 从HuggingFace加载,输入模型名称,即可加载对于的分词器
tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
# tokenizer 保存到本地
tokenizer.save_pretrained("./roberta_tokenizer")
# 从本地加载tokenizer
tokenizer = AutoTokenizer.from_pretrained("./roberta_tokenizer/")
tokens = tokenizer.tokenize(sen)
print(tokenizer.vocab)
print(tokenizer.vocab_size)
# 将词序列转换为id序列
ids = tokenizer.convert_tokens_to_ids(tokens)
# 将id序列转换为token序列
tokens = tokenizer.convert_ids_to_tokens(ids)
# 将token序列转换为string
str_sen = tokenizer.convert_tokens_to_string(tokens)
# 将字符串转换为id序列,又称之为编码
ids = tokenizer.encode(sen, add_special_tokens=True)
# 将id序列转换为字符串,又称之为解码
str_sen = tokenizer.decode(ids, skip_special_tokens=False)
# 填充
ids = tokenizer.encode(sen, padding="max_length", max_length=15)
# 截断
ids = tokenizer.encode(sen, max_length=5, truncation=True)
# 其他的输入
ids = tokenizer.encode(sen, padding="max_length", max_length=15)
attention_mask = [1 if idx != 0 else 0 for idx in ids]
token_type_ids = [0] * len(ids)
# 快捷调用方式
inputs = tokenizer.encode_plus(sen, padding="max_length", max_length=15)
inputs = tokenizer(sen, padding="max_length", max_length=15)
# 处理batch数据
sens = ["弱小的我也有大梦想",
"有梦想谁都了不起",
"追逐梦想的心,比梦想本身,更可贵"]
res = tokenizer(sens)
# Fast/Slow Tokenizer
sen = "弱小的我也有大Dreaming!"
fast_tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
slow_tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese", use_fast=False)
inputs = fast_tokenizer(sen, return_offsets_mapping=True)
print(inputs.word_ids)
# 指定天工tokenizer的加载
tokenizer = AutoTokenizer.from_pretrained("Skywork/Skywork-13B-base", trust_remote_code=True)
tokenizer.save_pretrained("skywork_tokenizer")
tokenizer = AutoTokenizer.from_pretrained("skywork_tokenizer", trust_remote_code=True)
tokenizer.decode(tokenizer.encode(sen))